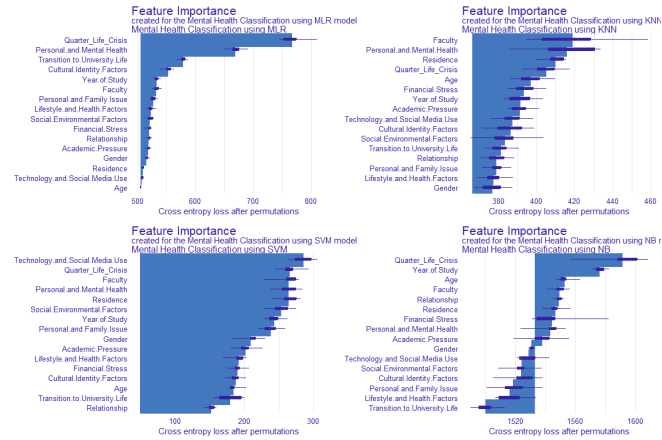
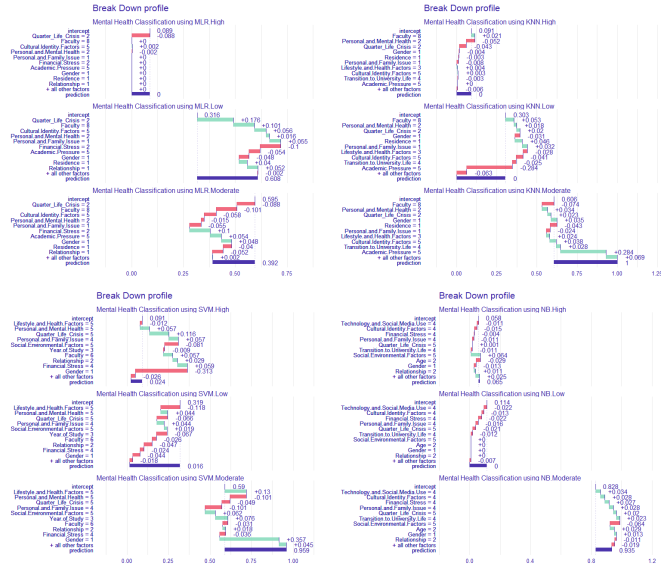
The mental health of university students has emerged as a critical global public health concern, with increasing prevalence of anxiety, depression, and stress-related conditions reported across diverse academic environments. With the increasing mental health issues among university students all over the world, there is an observable disparity in employing interpretable machine learning models to assess the risks of psychological distress, especially in resource-limited countries such as Kenya. This study bridges this gap by evaluating the predictive performance of selected single machine learning classifiers; Multinomial Logistic Regression (MLR), K-Nearest Neighbours (KNN), Support Vector Machine (SVM), and Naïve Bayes (NB) with Explainable Artificial Intelligences (XAI) in identifying levels of mental health distress (Low, Moderate, and High) among university students in Tharaka Nithi County, Kenya. A structured questionnaire was administered to a stratified random sample of 1500 students, capturing comprehensive data across demographic, academic, psychosocial, and behavioural dimensions. Data were preprocessed, encoded, and partitioned into 70% training and 30% testing sets. Models were developed using 10-fold cross-validation, with hyperparameter tuning performed via grid search. Explainable Artificial Intelligence (XAI) techniques, including SHAP (Shapley Additive Explanations) and model breakdown plots, were integrated to enhance transparency and interpretability of the model. The Support Vector Machine model demonstrated superior performance, with an overall accuracy of 97.6%, a Kappa coefficient of 0.957, and a perfect Area Under the Curve (AUC) score of 1.000 across all levels of mental distress. The model achieved a sensitivity of 1.000 for both High and Low distress, and 0.960 for Moderate, with precision values of 0.880, 0.960, and 1.000, respectively. KNN followed with an accuracy of 73.9% and Kappa of 0.471, while MLR and NB achieved accuracies of 69.7% and 68.8%, respectively. The SVM model emerged as the best model due to its ability to handle nonlinear and complex patterns in the data. SHAP analysis identified "Lifestyle and Health Factors," "Personal and Mental Health," "Academic Pressure," and "Quarter Life Crisis" as the most influential predictors across models. The study concludes that interpretable machine learning approaches, particularly SVM augmented with XAI, can provide highly accurate and actionable insights into student mental health. The study recommends integrating such models into institutional mental health surveillance frameworks to support early detection, personalized interventions, and policy planning, aligning with Sustainable Development Goal 3, which aims to ensure healthy lives and promote well-being for all.
| Published in | American Journal of Artificial Intelligence (Volume 9, Issue 2) |
| DOI | 10.11648/j.ajai.20250902.15 |
| Page(s) | 133-144 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Explainable AI, Machine Learning, Mental Health Distress, Quarter Life Crisis, SHAP Analysis, Support Vector Machine, University Students
Sample | Distress Levels | Total | ||
|---|---|---|---|---|
High | Low | Moderate | ||
Test | 30 | 106 | 201 | 337 |
8.9% | 31.5% | 59.6% | 100% | |
30% | 29.8% | 29.9% | 29.9% | |
Train | 70 | 250 | 471 | 791 |
8.8% | 31.6% | 59.5% | 100% | |
70% | 70.2% | 70.1% | 70.1% | |
Total | 100 | 356 | 672 | 1128 |
8.9% | 31.6% | 59.6% | 100% | |
100% | 100% | 100% | 100% | |
Metric | Single Classifier Model | |||
|---|---|---|---|---|
Multinomial Logistic Regression | K-Nearest Neighbors | Support Vector Machines | Naïve Bayes | |
Accuracy | 0.697 | 0.739 | 0.976 | 0.688 |
95% Confidence Interval | (0.645, 0.746) | (0.689, 0.785) | (0.954, 0.989) | (0.636, 0.738) |
No Information Rate | 0.596 | 0.596 | 0.596 | 0.596 |
P-Value (Acc > NIR) | 0.0001 | 0.0001 | < 2.2e-16 | 0.0003 |
Kappa | 0.390 | 0.471 | 0.957 | 0.332 |
McNemar's Test P-Value | 0.0001 | 0.0001 | NA | 0.0001 |
Metrics | MLR | k-Nearest Neighbors | Support Vector Machines | Naïve Bayes | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
High | Low | Moderate | High | Low | Moderate | High | Low | Moderate | High | Low | Moderate | |
Sensitivity | 0.600 | 0.380 | 0.880 | 0.400 | 0.490 | 0.920 | 1.000 | 1.000 | 0.960 | 0.333 | 0.311 | 0.940 |
Specificity | 0.960 | 0.920 | 0.460 | 0.970 | 0.930 | 0.540 | 0.990 | 0.980 | 1.000 | 0.971 | 0.965 | 0.353 |
PPV | 0.620 | 0.690 | 0.710 | 0.550 | 0.760 | 0.750 | 0.880 | 0.960 | 1.000 | 0.526 | 0.805 | 0.682 |
NPV | 0.960 | 0.760 | 0.720 | 0.940 | 0.800 | 0.820 | 1.000 | 1.000 | 0.940 | 0.937 | 0.753 | 0.800 |
Precision | NA | NA | NA | 0.550 | 0.760 | 0.750 | 0.880 | 0.960 | 1.000 | 0.526 | 0.805 | 0.682 |
Recall | NA | NA | NA | 0.400 | 0.490 | 0.920 | 1.000 | 1.000 | 0.960 | 0.333 | 0.311 | 0.940 |
F1 Score | NA | NA | NA | 0.460 | 0.600 | 0.830 | 0.940 | 0.980 | 0.980 | 0.408 | 0.449 | 0.791 |
Prevalence | 0.090 | 0.310 | 0.600 | 0.090 | 0.310 | 0.600 | 0.090 | 0.310 | 0.600 | 0.089 | 0.315 | 0.596 |
DR | 0.050 | 0.120 | 0.530 | 0.040 | 0.150 | 0.550 | 0.090 | 0.310 | 0.570 | 0.030 | 0.098 | 0.561 |
DP | 0.090 | 0.170 | 0.740 | 0.070 | 0.200 | 0.730 | 0.100 | 0.330 | 0.570 | 0.056 | 0.122 | 0.822 |
BA | 0.780 | 0.650 | 0.670 | 0.680 | 0.710 | 0.730 | 0.990 | 0.990 | 0.980 | 0.652 | 0.638 | 0.647 |
AUC | 0.934 | 0.707 | 0.712 | 0.906 | 0.849 | 0.831 | 1.000 | 1.000 | 1.000 | 0.870 | 0.683 | 0.715 |
ML | Machine Learning |
AI | Artificial Intelligence |
XAI | Explainable Artificial Intelligence |
MLR | Multinomial Logistic Regression |
KNN | K-Nearest Neighbors |
SVM | Support Vector Machine |
NB | Naïve Bayes |
ROC | Receiver Operating Characteristic |
AUC | Area Under the Curve |
SHAP | Shapley Additive Explanations |
| [1] | Sarker, I. H. (2021). Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Computer Science, 2(3). |
| [2] | L’Heureux, A., Grolinger, K., Elyamany, H. F., & Capretz, M. A. M. (2017). Machine Learning With Big Data: Challenges and Approaches. IEEE Access, 5, 7776-7797. |
| [3] | Ray, A., Bhardwaj, A., Malik, Y. K., Singh, S., & Gupta, R. (2022). Artificial intelligence and Psychiatry: An overview. Asian Journal of Psychiatry, 70, 103021. |
| [4] | Mofatteh, M. (2020). Risk factors associated with stress, anxiety, and depression among university undergraduate students. AIMS Public Health, 8(1), 36-65. |
| [5] | Kashif, M. F., Tabassum, R., & Bibi, S. (2024). Effects of Academic Stress on Mental Health Issues Among University Students. Journal of Social Sciences Development, 3(2), 170-182. |
| [6] | Beiter, R., Nash, R., McCrady, M., Rhoades, D., Linscomb, M., Clarahan, M., & Sammut, S. (2014). The prevalence and correlates of depression, anxiety, and stress in a sample of college students. Journal of Affective Disorders, 173, 90-96. |
| [7] | Campbell, F., Blank, L., Cantrell, A., Baxter, S., Blackmore, C., Dixon, J., & Goyder, E. (2022). Factors that influence mental health of university and college students in the UK: a systematic review. BMC Public Health, 22(1). |
| [8] |
WHO. (2021, November 17). Mental health of adolescents. Who. int; World Health Organization: WHO.
https://www.who.int/news-room/fact-sheets/detail/adolescent-mental-health |
| [9] | Kabir, R., Syed, H. Z., Vinnakota, D., Okello, S., Isigi, S. S., Abdul Kareem, S. K., Parsa, A. D., & Arafat, S. M. Y. (2024). Suicidal behaviour among university students in the UK: A systematic review. Heliyon, 10(2), e24069. |
| [10] | Dong, R., Dou, K., & Luo, J. (2023). Construction of a model for adolescent physical and mental health promotion based on the multiple mediating effects of general self-efficacy and sleep duration. BMC Public Health, 23(1). |
| [11] | El Morr, C., Jammal, M., Bou-Hamad, I., Hijazi, S., Ayna, D., Romani, M., & Reem Hoteit. (2024). Predictive Machine Learning Models for Assessing Lebanese University Students' Depression, Anxiety, and Stress During COVID-19. Journal of Primary Care & Community Health, 15. |
| [12] | Tang, H., Miri Rekavandi, A., Rooprai, D., Dwivedi, G., Sanfilippo, F. M., Boussaid, F., & Bennamoun, M. (2024). Analysis and Evaluation of Explainable Artificial Intelligence in Suicide Risk Assessment. Scientific Reports, 14(1). |
| [13] | Zhang, Y., Folarin, A. A., Stewart, C., Sankesara, H., Ranjan, Y., Conde, P., Choudhury, A. R., Sun, S., Rashid, Z., & Richard. (2025). An Explainable Anomaly Detection Framework for Monitoring Depression and Anxiety Using Consumer Wearable Devices. ArXiv.org. |
| [14] | Bhuiyan, M. I., Kamarudin, Nur Shazwani, & Ismail, N. H. (2025b). Enhanced Suicidal Ideation Detection from Social Media Using a CNN-BiLSTM Hybrid Model. ArXiv.org. |
| [15] | Thomas, J., Lucht, A., Segler, J., Wundrack, R., Miché, M., Lieb, R., Lars Kuchinke, & Gunther Meinlschmidt. (2024). Suicidality Prediction in Youth Crisis Text Line Users: Development and Validation of an Explainable Artificial Intelligence Text Classifier (Preprint). JMIR Public Health and Surveillance, 11, e63809-e63809. |
| [16] | Pendyala, V., & Kim, H. (2024). Assessing the Reliability of Machine Learning Models Applied to the Mental Health Domain Using Explainable AI. Electronics, 13(6), 1025. |
| [17] | Bergomi, L., Nicora, G., Orlowska, M. A., Chiara Podrecca, Riccardo Bellazzi, Fregosi, C., Salinaro, F., Bonzano, M., Crescenzi, G., Speciale, F., Pietro, S. D., Zuccaro, V., Asperges, E., Sacchi, P., Pietro Valsecchi, Pagani, E., Catalano, M., Bortolotto, C., Preda, L., & Enea Parimbelli. (2025). Which explanations do clinicians prefer? A comparative evaluation of XAI understandability and actionability in predicting the need for hospitalization. BMC Medical Informatics and Decision Making, 25(1). |
| [18] | Ntakolia, C., Dimitrios Priftis, Kotsis, K., Konstantina Magklara, Charakopoulou-Travlou, M., Ioanna Rannou, Konstantina Ladopoulou, Iouliani Koullourou, Emmanouil Tsalamanios, Lazaratou, E., Aspasia Serdari, Aliki Grigoriadou, Sadeghi, N., Chiu, K., & Ioanna Giannopoulou. (2023). Explainable AI-Based Identification of Contributing Factors to the Mood State Change in Children and Adolescents with Pre-Existing Psychiatric Disorders in the Context of COVID-19-Related Lockdowns in Greece. BioMedInformatics, 3(4), 1040-1059. |
| [19] | Pandey, M., Parmar, D., Mishra, S., & Pinjarkar, V. (2021). Mental Health Prediction for Juveniles Using Machine Learning Techniques. Social Science Research Network. |
| [20] | Votruba, N., & Thornicroft, G. (2016). Sustainable development goals and mental health: learnings from the contribution of the FundaMentalSDG global initiative. Global Mental Health, 3(26). |
| [21] | Capili, B. (2021). Cross-Sectional Studies. The American Journal of Nursing/American Journal of Nursing, 121(10), 59-62. |
| [22] | Ortiz, B. L. (2024). Data Preprocessing Techniques for Artificial Learning (AI)/Machine Learning (ML)-Readiness: Systematic Review of Wearable Sensor Data in Cancer Care. JMIR MHealth and UHealth. |
| [23] | Liu, H., & Cocea, M. (2017). Semi-random partitioning of data into training and test sets in a granular computing context. Granular Computing, 2(4), 357-386. |
| [24] | Yadav, S., & Shukla, S. (2016). Analysis of k-Fold Cross-Validation over Hold-Out Validation on Colossal Datasets for Quality Classification. 2016 IEEE 6th International Conference on Advanced Computing (IACC), 78-83. |
| [25] | Lumumba, V., Kiprotich, D., Mpaine, M., Makena, N., & Kavita, M. (2024). Comparative Analysis of Cross-Validation Techniques: LOOCV, K-folds Cross-Validation, and Repeated K-folds Cross-Validation in Machine Learning Models. American Journal of Theoretical and Applied Statistics, 13(5), 127-137. |
| [26] | Shahhosseini, M., Hu, G., & Pham, H. (2022). Optimizing ensemble weights and hyperparameters of machine learning models for regression problems. Machine Learning with Applications, 100251. |
| [27] | Wei, L., Jin, L., Yang, C., Chen, K., & Li, W. (2019). New Noise-Tolerant Neural Algorithms for Future Dynamic Nonlinear Optimization with Estimation on Hessian Matrix Inversion. IEEE Transactions on Systems Man and Cybernetics Systems, 51(4), 2611-2623. |
| [28] | Durge, A. R., & Shrimankar, D. D. (2024). DHFS-ECM: Design of a Dual Heuristic Feature Selection-based Ensemble Classification Model for the Identification of Bamboo Species from Genomic Sequences. Current Genomics, 25(3), 185-201. |
| [29] | Lumumba, V. W., Wanjuki, T. M., & Njoroge, E. W. (2025). Evaluating the Performance of Ensemble and Single Classifiers with Explainable Artificial Intelligence (XAI) on Hypertension Risk Prediction. Computational Intelligence and Machine Learning, 6(1). |
| [30] | Halder, R. K., Uddin, M. N., Uddin, M. A., Aryal, S., & Ansam Khraisat. (2024). Enhancing K-nearest neighbor algorithm: a comprehensive review and performance analysis of modifications. Journal of Big Data, 11(1). |
| [31] | Cunningham, P., & Delany, S. J. (2021). k-Nearest Neighbour Classifiers - A Tutorial. ACM Computing Surveys, 54(6), 1-25. |
| [32] | Peretz, O., Koren, M., & Koren, O. (2024). Naïve Bayes classifier - An ensemble procedure for recall and precision enrichment. Engineering Applications of Artificial Intelligence, 136, 108972. |
| [33] | Muriithi, D. K., Lumumba, V. W., Awe, O. O., & Muriithi, D. M. (2025). An Explainable Artificial Intelligence Model for Predicting Malaria Risk in Kenya. European Journal of Artificial Intelligence and Machine Learning, 4(1), 1-8. |
| [34] | Muriithi, D., Lumumba, V., & Okongo, M. (2024). A Machine Learning-Based Prediction of Malaria Occurrence in Kenya. American Journal of Theoretical and Applied Statistics, 13(4), 65-72. |
| [35] | Lee, Y.-G., Oh, J.-Y., Kim, D., & Kim, G. (2022). SHAP Value-Based Feature Importance Analysis for Short-Term Load Forecasting. Journal of Electrical Engineering & Technology, 18(1), 579-588. |
| [36] | Santos, M. R., Guedes, A., & Sanchez-Gendriz, I. (2024). SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis. Machine Learning and Knowledge Extraction, 6(1), 316-341. |
| [37] | Shatte, A. B. R., Hutchinson, D. M., & Teague, S. J. (2019). Machine learning in mental health: a scoping review of methods and applications. Psychological Medicine, 49(09), 1426-1448. |
APA Style
Lumumba, V. W., Muriithi, D. K., Oundo, M. (2025). Evaluating the Performance of Selected Single Classifiers with Incorporated Explainable Artificial Intelligence (XAI) in the Prediction of Mental Health Distress Among University Students. American Journal of Artificial Intelligence, 9(2), 133-144. https://doi.org/10.11648/j.ajai.20250902.15
ACS Style
Lumumba, V. W.; Muriithi, D. K.; Oundo, M. Evaluating the Performance of Selected Single Classifiers with Incorporated Explainable Artificial Intelligence (XAI) in the Prediction of Mental Health Distress Among University Students. Am. J. Artif. Intell. 2025, 9(2), 133-144. doi: 10.11648/j.ajai.20250902.15
AMA Style
Lumumba VW, Muriithi DK, Oundo M. Evaluating the Performance of Selected Single Classifiers with Incorporated Explainable Artificial Intelligence (XAI) in the Prediction of Mental Health Distress Among University Students. Am J Artif Intell. 2025;9(2):133-144. doi: 10.11648/j.ajai.20250902.15
@article{10.11648/j.ajai.20250902.15,
author = {Victor Wandera Lumumba and Dennis Kariuki Muriithi and Monicah Oundo},
title = {Evaluating the Performance of Selected Single Classifiers with Incorporated Explainable Artificial Intelligence (XAI) in the Prediction of Mental Health Distress Among University Students
},
journal = {American Journal of Artificial Intelligence},
volume = {9},
number = {2},
pages = {133-144},
doi = {10.11648/j.ajai.20250902.15},
url = {https://doi.org/10.11648/j.ajai.20250902.15},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajai.20250902.15},
abstract = {The mental health of university students has emerged as a critical global public health concern, with increasing prevalence of anxiety, depression, and stress-related conditions reported across diverse academic environments. With the increasing mental health issues among university students all over the world, there is an observable disparity in employing interpretable machine learning models to assess the risks of psychological distress, especially in resource-limited countries such as Kenya. This study bridges this gap by evaluating the predictive performance of selected single machine learning classifiers; Multinomial Logistic Regression (MLR), K-Nearest Neighbours (KNN), Support Vector Machine (SVM), and Naïve Bayes (NB) with Explainable Artificial Intelligences (XAI) in identifying levels of mental health distress (Low, Moderate, and High) among university students in Tharaka Nithi County, Kenya. A structured questionnaire was administered to a stratified random sample of 1500 students, capturing comprehensive data across demographic, academic, psychosocial, and behavioural dimensions. Data were preprocessed, encoded, and partitioned into 70% training and 30% testing sets. Models were developed using 10-fold cross-validation, with hyperparameter tuning performed via grid search. Explainable Artificial Intelligence (XAI) techniques, including SHAP (Shapley Additive Explanations) and model breakdown plots, were integrated to enhance transparency and interpretability of the model. The Support Vector Machine model demonstrated superior performance, with an overall accuracy of 97.6%, a Kappa coefficient of 0.957, and a perfect Area Under the Curve (AUC) score of 1.000 across all levels of mental distress. The model achieved a sensitivity of 1.000 for both High and Low distress, and 0.960 for Moderate, with precision values of 0.880, 0.960, and 1.000, respectively. KNN followed with an accuracy of 73.9% and Kappa of 0.471, while MLR and NB achieved accuracies of 69.7% and 68.8%, respectively. The SVM model emerged as the best model due to its ability to handle nonlinear and complex patterns in the data. SHAP analysis identified "Lifestyle and Health Factors," "Personal and Mental Health," "Academic Pressure," and "Quarter Life Crisis" as the most influential predictors across models. The study concludes that interpretable machine learning approaches, particularly SVM augmented with XAI, can provide highly accurate and actionable insights into student mental health. The study recommends integrating such models into institutional mental health surveillance frameworks to support early detection, personalized interventions, and policy planning, aligning with Sustainable Development Goal 3, which aims to ensure healthy lives and promote well-being for all.
},
year = {2025}
}
TY - JOUR T1 - Evaluating the Performance of Selected Single Classifiers with Incorporated Explainable Artificial Intelligence (XAI) in the Prediction of Mental Health Distress Among University Students AU - Victor Wandera Lumumba AU - Dennis Kariuki Muriithi AU - Monicah Oundo Y1 - 2025/08/30 PY - 2025 N1 - https://doi.org/10.11648/j.ajai.20250902.15 DO - 10.11648/j.ajai.20250902.15 T2 - American Journal of Artificial Intelligence JF - American Journal of Artificial Intelligence JO - American Journal of Artificial Intelligence SP - 133 EP - 144 PB - Science Publishing Group SN - 2639-9733 UR - https://doi.org/10.11648/j.ajai.20250902.15 AB - The mental health of university students has emerged as a critical global public health concern, with increasing prevalence of anxiety, depression, and stress-related conditions reported across diverse academic environments. With the increasing mental health issues among university students all over the world, there is an observable disparity in employing interpretable machine learning models to assess the risks of psychological distress, especially in resource-limited countries such as Kenya. This study bridges this gap by evaluating the predictive performance of selected single machine learning classifiers; Multinomial Logistic Regression (MLR), K-Nearest Neighbours (KNN), Support Vector Machine (SVM), and Naïve Bayes (NB) with Explainable Artificial Intelligences (XAI) in identifying levels of mental health distress (Low, Moderate, and High) among university students in Tharaka Nithi County, Kenya. A structured questionnaire was administered to a stratified random sample of 1500 students, capturing comprehensive data across demographic, academic, psychosocial, and behavioural dimensions. Data were preprocessed, encoded, and partitioned into 70% training and 30% testing sets. Models were developed using 10-fold cross-validation, with hyperparameter tuning performed via grid search. Explainable Artificial Intelligence (XAI) techniques, including SHAP (Shapley Additive Explanations) and model breakdown plots, were integrated to enhance transparency and interpretability of the model. The Support Vector Machine model demonstrated superior performance, with an overall accuracy of 97.6%, a Kappa coefficient of 0.957, and a perfect Area Under the Curve (AUC) score of 1.000 across all levels of mental distress. The model achieved a sensitivity of 1.000 for both High and Low distress, and 0.960 for Moderate, with precision values of 0.880, 0.960, and 1.000, respectively. KNN followed with an accuracy of 73.9% and Kappa of 0.471, while MLR and NB achieved accuracies of 69.7% and 68.8%, respectively. The SVM model emerged as the best model due to its ability to handle nonlinear and complex patterns in the data. SHAP analysis identified "Lifestyle and Health Factors," "Personal and Mental Health," "Academic Pressure," and "Quarter Life Crisis" as the most influential predictors across models. The study concludes that interpretable machine learning approaches, particularly SVM augmented with XAI, can provide highly accurate and actionable insights into student mental health. The study recommends integrating such models into institutional mental health surveillance frameworks to support early detection, personalized interventions, and policy planning, aligning with Sustainable Development Goal 3, which aims to ensure healthy lives and promote well-being for all. VL - 9 IS - 2 ER -
Center for Data Analytics and Modeling, Chuka University, Chuka, Kenya
Center for Data Analytics and Modeling, Chuka University, Chuka, Kenya
Department of Physical Science, Chuka University, Chuka, Kenya
Information