Drought poses a significant threat to essential resources like food, land, and public health. Machine Learning (ML) has emerged as a powerful tool in weather forecasting, leveraging algorithms to predict weather phenomena with remarkable accuracy. ML models excel in navigating complex atmospheric systems, including those affected by climate change, offering precision beyond traditional forecasting methods. However, predicting drought remains challenging due to its uneven distribution and varying degrees. To tackle this challenge, an exploration of a novel approach of combining K-means++ clustering and Gradient Boosting Algorithm (KGBA) with Principal Component Analysis (PCA) for dimensionality reduction was carried out. Using a dataset spanning from 2000 to July 2016, comprising 2,756,796 US Drought Monitor records, the study developed and evaluated the KGBA model's effectiveness in drought prediction. The results demonstrated the superiority of high precision and recall rates, particularly in forecasting extreme and exceptional drought periods. Specifically, KGBA attained precision accuracies of 33% and 74%, along with recall rates of 72% and 77% for predicting extreme and exceptional drought periods, respectively. The model had an overall accuracy of 46% in predicting all the multiple classes of droughts. A performance that is slightly better than other ensemble methods that had the closest performance. These findings underscore the potential of KGBA in enhancing the predictive capabilities for drought mitigation efforts, as it outperformed other models such as Gradient Boosting, Random Forest, Bayes Naive, and K-Nearest Neighbor.
| Published in | American Journal of Data Mining and Knowledge Discovery (Volume 9, Issue 1) |
| DOI | 10.11648/j.ajdmkd.20240901.11 |
| Page(s) | 1-19 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
K-means++, Gradient Boosting, Drought, Principal Component Analysis, Machine Learning and Climate Change
S/N | Attributes | Description |
|---|---|---|
1. | WS10M_MIN | Minimum Wind Speed at 10 Meters (m/s) |
2. | QV2M | Specific Humidity at 2 Meters (g/kg) |
3. | T2M_RANGE | Temperature Range at 2 Meters (C) |
4. | WS10M | Wind Speed at 10 Meters (m/s) |
5. | T2M | Temperature at 2 Meters (C) |
6. | WS50M_MIN | Minimum Wind Speed at 50 Meters (m/s) |
7. | T2M_MAX | Maximum Temperature at 2 Meters (C) |
8. | WS50M | Wind Speed at 50 Meters (m/s) |
9. | TS | Earth Skin Temperature (C) |
10. | WS50M_RANGE | Wind Speed Range at 50 Meters (m/s) |
11. | WS50M_MAX | Maximum Wind Speed at 50 Meters (m/s) |
12. | WS10M_MAX | Maximum Wind Speed at 10 Meters (m/s) |
13. | WS10M_RANGE | Wind Speed Range at 10 Meters (m/s) |
14. | PS | Surface Pressure (kPa) |
15. | T2MDEW | Dew/Frost Point at 2 Meters (C) |
16. | T2M_MIN | Minimum Temperature at 2 Meters (C) |
17. | T2MWET | Wet Bulb Temperature at 2 Meters (C) |
18. | PRECTOT | Precipitation (mm day-1) |
S/N | Label | Description |
|---|---|---|
a. | None | Drought Absent |
b. | D0 | Abnormally dry |
c. | D1 | Moderate drought |
d. | D2 | Severe drought |
e. | D3 | Extreme drought |
f. | D4 | Exceptional drought |
S/N | Feature | Kurtosis values | S/N | Feature | Kurtosis values |
|---|---|---|---|---|---|
1. | fips | -1.10 | 13. | WS10M_MAX | 0.70 |
2. | PRECTOT | 33.30 | 14. | WS10M_MIN | 3.15 |
3. | PS | 4.81 | 15. | WS10M_RANGE | 2.08 |
4. | QV2M | -0.78 | 16. | WS50M | 0.81 |
5. | T2M | 0.55 | 17. | WS50M_MAX | 0.98 |
6. | T2MDEW | -0.73 | 18. | WS50M_MIN | 0.59 |
7. | T2MWET | -0.75 | 19. | WS50M_RANGE | 2.20 |
8. | T2M_MAX | -0.50 | 20. | Score | 1.38 |
9. | T2M_MIN | -0.44 | 21. | Year | 1.20 |
10. | T2M_RANGE | -0.31 | 22. | month | 1.20 |
11. | TS | -0.53 | 23. | day | 1.19 |
12. | WS10M | 1.41 |
precision | recall | f1-score | Support | |
|---|---|---|---|---|
Class 0 | 0.57 | 0.50 | 0.53 | 10904 |
Class 1 | 0.56 | 0.23 | 0.33 | 10737 |
Class 2 | 0.69 | 0.16 | 0.26 | 10880 |
Class 3 | 0.28 | 0.34 | 0.31 | 10932 |
Class 4 | 0.33 | 0.72 | 0.45 | 10890 |
Class 5 | 0.75 | 0.78 | 0.76 | 10803 |
Accuracy | 0.46 | 65146 | ||
macro avg | 0.53 | 0.46 | 0.44 | 65146 |
weighted avg | 0.53 | 0.46 | 0.44 | 65146 |
Class Name | precision | recall | f1-score | support |
|---|---|---|---|---|
Class 0 | 0.56 | 0.49 | 0.52 | 10904 |
Class 1 | 0.53 | 0.23 | 0.32 | 10737 |
Class 2 | 0.68 | 0.15 | 0.25 | 10880 |
Class 3 | 0.28 | 0.35 | 0.31 | 10932 |
Class 4 | 0.33 | 0.72 | 0.45 | 10890 |
Class 5 | 0.74 | 0.77 | 0.76 | 10803 |
accuracy | 0.45 | 65146 | ||
macro avg | 0.52 | 0.45 | 0.43 | 65146 |
weighted avg | 0.52 | 0.45 | 0.43 | 65146 |
Class Name | precision | Recall | f1-score | Support |
|---|---|---|---|---|
Class 0 | 0.6095 | 0.6039 | 0.6067 | 10904 |
Class 1 | 0.4020 | 0.3868 | 0.3943 | 10737 |
Class 2 | 0.2748 | 0.2707 | 0.2727 | 10880 |
Class 3 | 0.1716 | 0.1701 | 0.1709 | 10932 |
Class 4 | 0.1565 | 0.1680 | 0.1620 | 10890 |
Class 5 | 0.8606 | 0.8578 | 0.8592 | 10803 |
accuracy | 0.4089 | 65146 | ||
macro avg | 0.4125 | 0.4095 | 0.4110 | 65146 |
weighted avg | 0.4118 | 0.4089 | 0.4103 | 65146 |
Class Name | precision | recall | f1-score | support |
|---|---|---|---|---|
Class 0 | 0.3554 | 0.4534 | 0.3985 | 10904 |
Class 1 | 0.2651 | 0.2493 | 0.2570 | 10737 |
Class 2 | 0.1807 | 0.1833 | 0.1820 | 10880 |
Class 3 | 0.1472 | 0.1452 | 0.1462 | 10932 |
Class 4 | 0.2031 | 0.1811 | 0.1915 | 10890 |
Class 5 | 0.6855 | 0.6098 | 0.6455 | 10803 |
accuracy | 0.3033 | 65146 | ||
macro avg | 0.3062 | 0.3037 | 0.3034 | 65146 |
weighted avg | 0.3057 | 0.3033 | 0.3030 | 65146 |
Class Name | precision | recall | f1-score | support |
|---|---|---|---|---|
Class 0 | 0.2647 | 0.1045 | 0.1499 | 10904 |
Class 1 | 0.1584 | 0.0392 | 0.0629 | 10737 |
Class 2 | 0.1171 | 0.0342 | 0.0529 | 10880 |
Class 3 | 0.0639 | 0.0369 | 0.0467 | 10932 |
Class 4 | 0.2375 | 0.9366 | 0.3789 | 10890 |
Class 5 | 0.4070 | 0.2164 | 0.2826 | 10803 |
accuracy | 0.2283 | 65146 | ||
macro avg | 0.2081 | 0.2280 | 0.1623 | 65146 |
weighted avg | 0.2079 | 0.2283 | 0.1623 | 65146 |
CC | Climate Change |
MLM | Machine Learning Model |
RF | Random Forest |
GBA | Gradient Boosting Algorithm |
KGBA | K-means++ Clustering and Gradient Boosting Algorithm |
XGBA | Extreme Gradient Boosting Algorithm |
LightGBA | Light Gradient Boosting Algorithm |
PCA | Principal Component Analysis |
ML | Machine Learning |
SVM | Support Vector Machine |
ANN | Artificial Neural Networks |
ELM | Extreme Learning Machine (ELM) |
SPI | Standardized Precipitation |
I | Drought Index |
Ped | Ped Index |
SWAT | Soil and Water Assessment Tool |
NDMC | National Drought Mitigation |
| [1] |
NOS Science Report 2021
https://oceanservice.noaa.gov/about/nos-science-report/2021/ accessed 02 May 2023. |
| [2] | Mortuza, M. R., Moges, E., Demissie, Y., & Li, H. Y. (2019). Historical and future drought in Bangladesh using copula-based bivariate regional frequency analysis. Theoretical and Applied Climatology, 135(3–4), 855–871. |
| [3] | Khan, N., Sachindra, D. A., Shahid, S., Ahmed, K., Shiru, M. S., & Nawaz, N. (2020). Prediction of droughts over Pakistan using machine learning algorithms. Advances in Water Resources, 139. |
| [4] | Barua, S., Ng, A. W. M., & Perera, B. J. C. (2012). Artificial Neural Network–Based Drought Forecasting Using a Nonlinear Aggregated Drought Index. Journal of Hydrologic Engineering, 17(12), 1408–1413. |
| [5] | Ghimire, S., Deo, R. C., Downs, N. J., & Raj, N. (2019). Global solar radiation prediction by ANN integrated with European Centre for medium range weather forecast fields in solar rich cities of Queensland Australia. Journal of Cleaner Production, 216, 288–310. |
| [6] | Xiang, B., Lin, S. J., Zhao, M., Johnson, N. C., Yang, X., & Jiang, X. (2019). Subseasonal Week 3–5 Surface Air Temperature Prediction During Boreal Wintertime in a GFDL Model. Geophysical Research Letters, 46(1), 416–425. |
| [7] | Yang, T., Zhou, X., Yu, Z., Krysanova, V., & Wang, B. (2015). Drought projection based on a hybrid drought index using Artificial Neural Networks. Hydrological Processes, 29(11), 2635–2648. |
| [8] | Jolliffe, I. T. (2002). Principal component analysis for special types of data (pp. 338-372). Springer, New York. |
| [9] |
Sidak, K. (2023, December). Overview of Principal Component Analysis (PCA).
https://codefinity.com/blog/Overview-of-Principal-Component-Analysis-(PCA) accessed 02 May 2023. |
| [10] | Mokhtar, A., Jalali, M., He, H., Al-Ansari, N., Elbeltagi, A., Alsafadi, K., Abdo, H. G., Sammen, S. S., Gyasi-Agyei, Y., & Rodrigo-Comino, J. (2021). Estimation of SPEI Meteorological Drought Using Machine Learning Algorithms. IEEE Access, 9, 65503–65523. |
| [11] | Jiang, W., & Luo, J. (2021). An Evaluation of Machine Learning and Deep Learning Models for Drought Prediction using Weather Data. |
| [12] | Gan, T. Y., Ito, M., Hülsmann, S., Qin, X., Lu, X. X., Liong, S. Y., Rutschman, P., Disse, M., & Koivusalo, H. (2016). Possible climate change/variability and human impacts, vulnerability of drought-prone regions, water resources and capacity building for Africa. Hydrological Sciences Journal, 61(7), 1209–1226. |
| [13] | Ayinla, B., & Akinola, S. O. (2021). An Improved Collaborative Pruning Using Ant Colony Optimization and Pessimistic Technique of C5.0 Decision Tree Algorithm. Article in International Journal of Computer Science and Information Security. |
| [14] | Zhong, R., Chen, X., Lai, C., Wang, Z., Lian, Y., Yu, H., & Wu, X. (2019). Drought monitoring utility of satellite-based precipitation products across mainland China. Journal of Hydrology, 568, 343–359. |
| [15] | Breiman, L. (1997). ARCING THE EDGE. |
| [16] | Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189–1232. |
| [17] | Friedman, J. H. (2002). Stochastic gradient boosting. Computational Statistics and Data Analysis, 38(4), 367–378. |
| [18] | Mason, L., Bartlett, P., Baxter, J., & Frean, M. (2000). Boosting Algorithm as Gradient Descent. Advances in Neural Information Processing Systems, 512–518. |
| [19] | Bentéjac, C., Csörgő, A., & Martínez-Muñoz, G. (2021). A Comparative Analysis of XGBoost. Artificial Intelligence Review, 54, 1937–1967. |
| [20] | Friedman, J., Hastie, T., & Tibshirani, R. (2000). ADDITIVE LOGISTIC REGRESSION: A STATISTICAL VIEW OF BOOSTING. In The Annals of Statistics (Vol. 28, Issue 2). |
| [21] | Breiman, L. (2001). Random forests. Kluwer Academic Publishers, Netherlands 45(1), 5–32. |
| [22] | Luo, H., Bhardwaj, J., Choy, S., & Kuleshov, Y. (2022). Applying Machine Learning for Threshold Selection in Drought Early Warning System. Climate, 10(7). |
| [23] | Felsche, E., & Ludwig, R. (n.d.). Applying machine learning for drought prediction using data from a large ensemble of climate simulations. |
| [24] | Likas, A., Vlassis, N., & Verbeek, J. (n.d.). The global k-means clustering algorithm The global k-means clustering algorithm. [Technical. |
| [25] | Tri, D. Q., Dat, T. T., & Truong, D. D. (2019). Application of meteorological and hydrological drought indices to establish drought classification maps of the Ba River basin in Vietnam. Hydrology, 6(2). |
| [26] |
Christoph, M. (2021, July 23). Predict Droughts using Weather & Soil Data.
https://www.kaggle.com/datasets/cdminix/us-drought-meteorological-data accessed 18 May 2023 |
| [27] |
Nitin. (2020, April 22). LightGBM Binary Classification, Multi-Class Classification, Regression using Python.
Https://Nitin9809.Medium.Com/Lightgbm-Binary-Classification-Multi-Class-Classification-Regression-Using-Python-4f22032b36a2 accessed 18 May 2023 |
| [28] |
Amber, T., & US, D. M. (2021). amberthomas/us-drought-monitor | Workspace | data. world.
https://data.world/amberthomas/us-drought-monitor/workspace/project-summary?agentid=amberthomas&datasetid=us-drought-monitor accessed 20 May 2023 |
APA Style
Ayinla, B. I., Abdulsalam, R. A. (2024). Exploring a Novel Approach of K-mean Gradient Boosting Algorithm with PCA for Drought Prediction. American Journal of Data Mining and Knowledge Discovery, 9(1), 1-19. https://doi.org/10.11648/j.ajdmkd.20240901.11
ACS Style
Ayinla, B. I.; Abdulsalam, R. A. Exploring a Novel Approach of K-mean Gradient Boosting Algorithm with PCA for Drought Prediction. Am. J. Data Min. Knowl. Discov. 2024, 9(1), 1-19. doi: 10.11648/j.ajdmkd.20240901.11
AMA Style
Ayinla BI, Abdulsalam RA. Exploring a Novel Approach of K-mean Gradient Boosting Algorithm with PCA for Drought Prediction. Am J Data Min Knowl Discov. 2024;9(1):1-19. doi: 10.11648/j.ajdmkd.20240901.11
@article{10.11648/j.ajdmkd.20240901.11,
author = {Babatunde Isaiah Ayinla and Rasheedat Aderonke Abdulsalam},
title = {Exploring a Novel Approach of K-mean Gradient Boosting Algorithm with PCA for Drought Prediction
},
journal = {American Journal of Data Mining and Knowledge Discovery},
volume = {9},
number = {1},
pages = {1-19},
doi = {10.11648/j.ajdmkd.20240901.11},
url = {https://doi.org/10.11648/j.ajdmkd.20240901.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajdmkd.20240901.11},
abstract = {Drought poses a significant threat to essential resources like food, land, and public health. Machine Learning (ML) has emerged as a powerful tool in weather forecasting, leveraging algorithms to predict weather phenomena with remarkable accuracy. ML models excel in navigating complex atmospheric systems, including those affected by climate change, offering precision beyond traditional forecasting methods. However, predicting drought remains challenging due to its uneven distribution and varying degrees. To tackle this challenge, an exploration of a novel approach of combining K-means++ clustering and Gradient Boosting Algorithm (KGBA) with Principal Component Analysis (PCA) for dimensionality reduction was carried out. Using a dataset spanning from 2000 to July 2016, comprising 2,756,796 US Drought Monitor records, the study developed and evaluated the KGBA model's effectiveness in drought prediction. The results demonstrated the superiority of high precision and recall rates, particularly in forecasting extreme and exceptional drought periods. Specifically, KGBA attained precision accuracies of 33% and 74%, along with recall rates of 72% and 77% for predicting extreme and exceptional drought periods, respectively. The model had an overall accuracy of 46% in predicting all the multiple classes of droughts. A performance that is slightly better than other ensemble methods that had the closest performance. These findings underscore the potential of KGBA in enhancing the predictive capabilities for drought mitigation efforts, as it outperformed other models such as Gradient Boosting, Random Forest, Bayes Naive, and K-Nearest Neighbor.
},
year = {2024}
}
TY - JOUR T1 - Exploring a Novel Approach of K-mean Gradient Boosting Algorithm with PCA for Drought Prediction AU - Babatunde Isaiah Ayinla AU - Rasheedat Aderonke Abdulsalam Y1 - 2024/07/23 PY - 2024 N1 - https://doi.org/10.11648/j.ajdmkd.20240901.11 DO - 10.11648/j.ajdmkd.20240901.11 T2 - American Journal of Data Mining and Knowledge Discovery JF - American Journal of Data Mining and Knowledge Discovery JO - American Journal of Data Mining and Knowledge Discovery SP - 1 EP - 19 PB - Science Publishing Group SN - 2578-7837 UR - https://doi.org/10.11648/j.ajdmkd.20240901.11 AB - Drought poses a significant threat to essential resources like food, land, and public health. Machine Learning (ML) has emerged as a powerful tool in weather forecasting, leveraging algorithms to predict weather phenomena with remarkable accuracy. ML models excel in navigating complex atmospheric systems, including those affected by climate change, offering precision beyond traditional forecasting methods. However, predicting drought remains challenging due to its uneven distribution and varying degrees. To tackle this challenge, an exploration of a novel approach of combining K-means++ clustering and Gradient Boosting Algorithm (KGBA) with Principal Component Analysis (PCA) for dimensionality reduction was carried out. Using a dataset spanning from 2000 to July 2016, comprising 2,756,796 US Drought Monitor records, the study developed and evaluated the KGBA model's effectiveness in drought prediction. The results demonstrated the superiority of high precision and recall rates, particularly in forecasting extreme and exceptional drought periods. Specifically, KGBA attained precision accuracies of 33% and 74%, along with recall rates of 72% and 77% for predicting extreme and exceptional drought periods, respectively. The model had an overall accuracy of 46% in predicting all the multiple classes of droughts. A performance that is slightly better than other ensemble methods that had the closest performance. These findings underscore the potential of KGBA in enhancing the predictive capabilities for drought mitigation efforts, as it outperformed other models such as Gradient Boosting, Random Forest, Bayes Naive, and K-Nearest Neighbor. VL - 9 IS - 1 ER -
Department of Computer Science, University of Ibadan, Ibadan, Nigeria
Biography: Babatunde Isaiah Ayinla is a distinguished Computer Science lecturer at the University of Ibadan, Nigeria, where he bagged both his M.Sc. and Ph.D. His academic journey includes a fellowship at the College of Charleston, USA, in 2002. Specialising in cybersecurity, machine learning, and data science, Dr. Ayinla contributes significantly to the field through teaching and research. He imparts essential programming skills to students and supervises Master's dissertations, shaping future computer scientists. His expertise in developing robust cybersecurity systems, creating intelligent machine learning algorithms, and extracting insights from complex datasets makes him a valuable asset in the evolving landscape of computer science. Dr. Ayinla is currently en route to the Federal University of Lavras, Brazil, to pursue postdoctoral research in the Department of Automatic and System Engineering. His academic achievements and practical experience position him as an influential figure in advancing computer science knowledge and applications.

Department of Computer Science, University of Ibadan, Ibadan, Nigeria
Biography: Rasheedat Aderonke Abdulsalam hails from Saki, Oyo State, Nigeria. She has an MSc. in Computer Science from the prestigious University of Ibadan and a BSc. in Computer Science from Alhikmah University. With her background in computer science, she has built a career and is currently working as a Technical Writer at FlowCentral Technologies and as a Program Analyst at the MIS Unit, Federal College of Education (Special), Oyo. As a Technical Writer, Abdulsalam excels in creating detailed documentation and user guides that make technical materials understandable to any audience. At the MIS Center, she uses her analytical skills to create and manage information systems that improve the institution's operational efficiency. She is a member of the Nigeria Computer Society and the Computer Professionals Registration Council of Nigeria. Her dedication to these organizations is a reflection of her passion to stay abreast of technological advancements and contribute to its development.

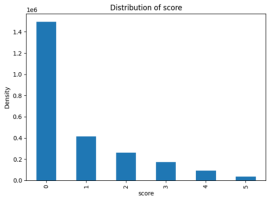
Figure 1. The Data Distribition according to the target variable.
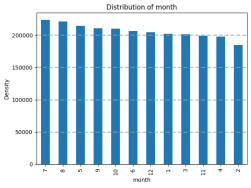
Figure 2. The Data Distribition according to the months of the year.
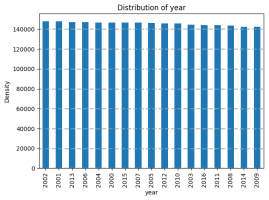
Figure 3. The Data distribution according to the years.
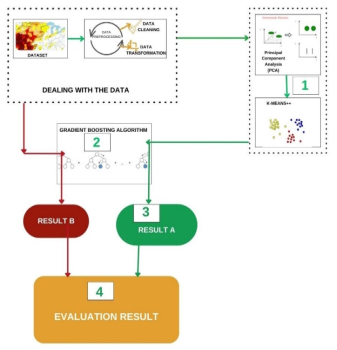
Figure 4. Generic Architecture of KGBA Model.
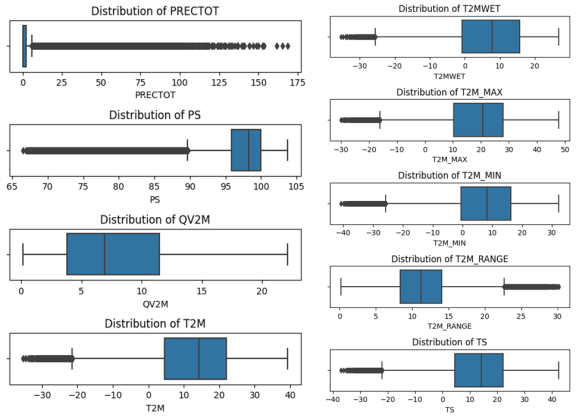
Figure 6. The univariant Features’ Outlier Analysis.
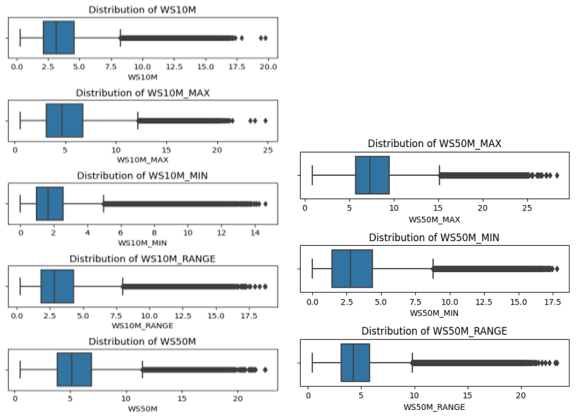
Figure 7. The Univariant Features’ Outlier Analysis.
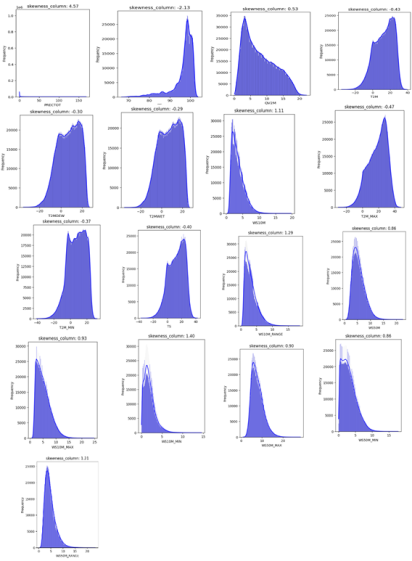
Figure 8. The Skewed Analysis of the Dependent Variables.
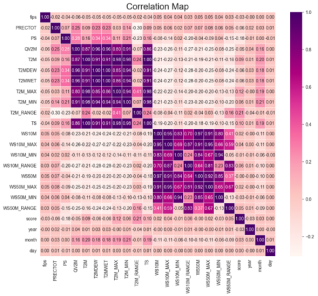
Figure 9. Correlation Plot For Feature Selection.
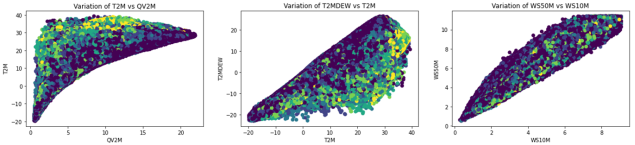
Figure 10. The Bi-variance Correlation between some Dependent Variables.
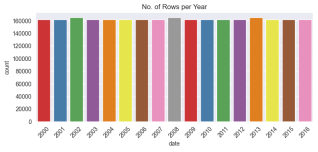
Figure 11. An Overview of Numbers of Tuples Across 17 Year.
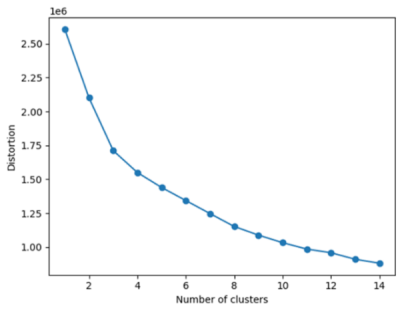
Figure 12. The Elbow Method To Determine Number of Clusters.
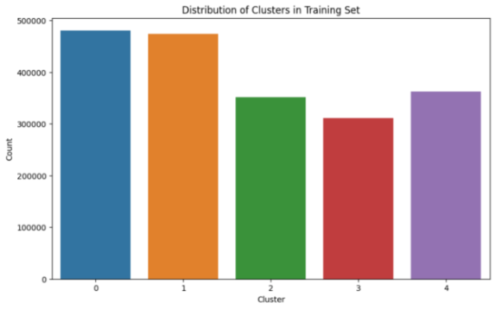
Figure 13. Training Dataset Distribution After PCA and K++Mean According To Each Class.
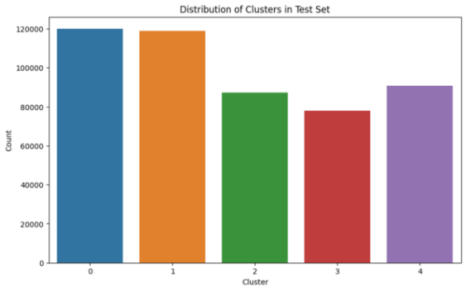
Figure 14. Test Dataset Distribution After PCA and K++Mean According To Each Class.
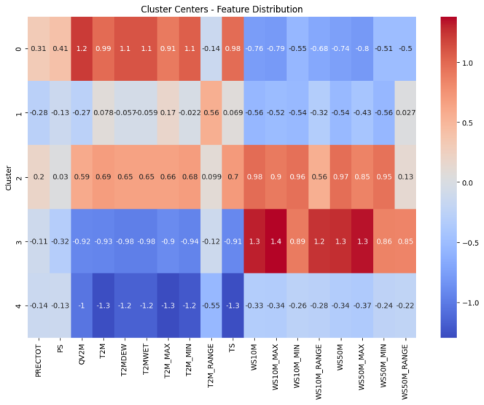
Figure 15. Data Clusters During PCA.
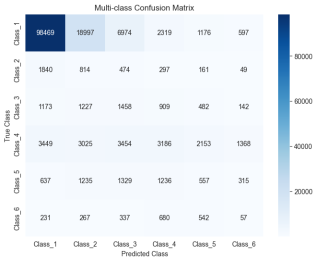
Figure 16. Confusion matrix for K-Means++ Gradient Boosting Algorithm (KGBA).
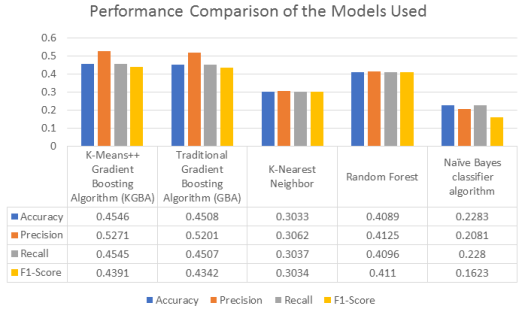
Figure 17. Performance Comparison of the model used.
Information


