The study aimed to determine the survival rate of first-class passengers using the Titanic dataset from Kaggle. Descriptive statistics revealed that first class passengers had way more chance to survive as compared to other classes, which underscores the role of socioeconomic status in determining chances of survival. Evaluation metrics, which assess model performance independently for male and female cohorts, shed light on gender specific projected accuracy. The analysis of propensity scores matching data for male and female passengers separately ensured that each gender category had control groups and treatments that were equally distributed. It was discovered that women had higher survival rates compared to men and these findings also identified disparities in the levels of surviving among genders. Improvements in covariate balance were indicated by post-matching statistics for both the male and female cohorts, indicating that the matching process was successful for both genders. The treatment effect estimates for male and female passengers were computed independently, and the findings showed that a number of characteristics significantly improved the survival rates for each gender group. The overall results of the study emphasized how important it is to include gender when analyzing survival outcomes using the Titanic dataset. In addition, age was suggested as an important factor whereby young people had higher chances of being saved.
| Published in | American Journal of Mathematical and Computer Modelling (Volume 9, Issue 3) |
| DOI | 10.11648/j.ajmcm.20240903.12 |
| Page(s) | 68-77 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Propensity Score Matching, Survival Rates, Observational Data, Treatment and Control Groups
Max | Count | Mean | Std | Min | 25% | 50% | 75% |
|---|---|---|---|---|---|---|---|
False | 528.00 | 0.32 | 0.47 | 0.00 | 0.00 | 0.00 | 0.00 |
1.00 | |||||||
True | 186.00 | 0.66 | 0.48 | 0.00 | 0.00 | 1.00 | 1.00 |
1.00 |
Survived | is_pclass1 | is male | Age | Proba | Logit | Pred |
|---|---|---|---|---|---|---|
0 | 0 | False | True | 22.00 | 0.12 | -1.98 |
0 | ||||||
1 | 1 | True | False | 38.00 | 0.44 | -0.22 |
0 | ||||||
1 | 0 | False | False | 26.00 | 0.28 | -0.96 |
0 | ||||||
1 | 1 | True | False | 35.00 | 0.40 | -0.41 |
0 | ||||||
0 | 0 | False | True | 35.00 | 0.24 | -1.18 |
0 |
Metric | Value |
|---|---|
Accuracy | 0.7591 |
ROC | AUC 0.7467 |
F1-score | 0.3435 |
False | True | |
|---|---|---|
False | 497 | 31 |
True | 141 | 45 |
Distance | Survived | is_Pclass1 | is Male | Age | Proba | Logit | Pred | Match |
|---|---|---|---|---|---|---|---|---|
243 | 1 | True | True | 0.92 | 0.04 | -3.27 | 0 | 59.00 |
-0.01 | ||||||||
357 | 1 | True | True | 4.00 | 0.04 | -3.08 | 0 | 154.00 |
-0.06 | ||||||||
639 | 1 | True | True | 11.00 | 0.07 | -2.65 | 0 | 44.00 |
0.00 | ||||||||
240 | 0 | True | False | 2.00 | 0.08 | -2.44 | 0 | 94.00 |
0.00 | ||||||||
437 | 1 | True | True | 17.00 | 0.09 | -2.28 | 0 | 346.00 |
0.00 | ||||||||
74 | 0 | True | True | 71.00 | 0.74 | 1.04 | 1 | 91.00 |
-0.03 | ||||||||
293 | 1 | True | False | 60.00 | 0.76 | 1.13 | 1 | 91.00 |
-0.12 | ||||||||
662 | 1 | True | False | 62.00 | 0.78 | 1.26 | 1 | 91.00 |
-0.25 | ||||||||
221 | 1 | True | False | 63.00 | 0.79 | 1.32 | 1 | 679.00 |
-0.09 | ||||||||
498 | 1 | True | True | 80.00 | 0.83 | 1.60 | 1 | 679.00 |
-0.37 |
Distance | Survived | is_Pclass1 | is_Male | Age | Proba | Logit | Pred | Match |
|---|---|---|---|---|---|---|---|---|
0 | 0 | 1 | True | True | 0.92 | 0.04 | -3.27 | 0 |
59.00 | -0.01 | |||||||
1 | 1 | 1 | True | True | 4.00 | 0.04 | -3.08 | 0 |
154.00 | -0.06 | |||||||
2 | 2 | 1 | True | True | 11.00 | 0.07 | -2.65 | 0 |
44.00 | 0.00 | |||||||
3 | 3 | 0 | True | False | 2.00 | 0.08 | -2.44 | 0 |
94.00 | 0.00 | |||||||
4 | 4 | 1 | True | True | 17.00 | 0.09 | -2.28 | 0 |
346.00 | 0.00 | |||||||
367 | 367 | 0 | False | True | 70.50 | 0.73 | 1.01 | 1 |
NaN | NaN | |||||||
368 | 368 | 0 | False | True | 70.50 | 0.73 | 1.01 | 1 |
NaN | NaN | |||||||
369 | 369 | 0 | False | True | 70.50 | 0.73 | 1.01 | 1 |
NaN | NaN | |||||||
370 | 370 | 0 | False | True | 74.00 | 0.77 | 1.23 | 1 |
NaN | NaN | |||||||
371 | 371 | 0 | False | True | 74.00 | 0.77 | 1.23 | 1 |
NaN | NaN |
age_t | is_male_t | survived_t | match | age_c | is_male_c | survived_c | |
|---|---|---|---|---|---|---|---|
243 | 0.92 | True | 1 | 59.00 | 0.83 | True | 1 |
357 | 4.00 | True | 1 | 154.00 | 3.00 | True | 1 |
639 | 11.00 | True | 1 | 44.00 | 11.00 | True | 0 |
240 | 2.00 | False | 0 | 94.00 | 2.00 | False | 0 |
437 | 17.00 | True | 1 | 346.00 | 17.00 | True | 0 |
74 | 71.00 | True | 0 | 91.00 | 70.50 | True | 0 |
293 | 60.00 | False | 1 | 91.00 | 70.50 | True | 0 |
662 | 62.00 | False | 1 | 91.00 | 70.50 | True | 0 |
221 | 63.00 | False | 1 | 679.00 | 74.00 | True | 0 |
498 | 80.00 | True | 1 | 679.00 | 74.00 | True | 0 |
Logit | After matching | ||||||||
|---|---|---|---|---|---|---|---|---|
count | mean | std | min | 25% | 50% | 75% | max | |
is_pclass1 False | 528.00 | -1.43 | 0.85 | -3.31 | -2.04 | -1.48 | -0.90 | 1.32 |
is_pclass1 True | 186.00 | -0.63 | 0.91 | -3.27 | -1.26 | -0.58 | -0.01 | 1.60 |
Logit | After matching | ||||||||
count | mean | std | min | 25% | 50% | 75% | max | |
is_pclass1 False | 186.00 | -0.65 | 0.88 | -3.28 | -1.26 | -0.61 | -0.04 | 1.23 |
is_pclass1 True | 186.00 | -0.63 | 0.91 | -3.27 | -1.26 | -0.58 | -0.01 | 1.60 |
Age | Before matching | ||||||||
count | mean | std | min | 25% | 50% | 75% | max | |
is_pclass1 False | 528.00 | 26.69 | 13.18 | 0.42 | 19.00 | 26.00 | 34.00 | 74.00 |
is_pclass1 True | 186.00 | 38.23 | 0.92 | 14.80 | 27.00 | 37.00 | 49.00 | 80.00 |
Age | After matching | ||||||||
count | mean | std | min | 25% | 50% | 75% | max | |
is_pclass1 False | 186.00 | 37.84 | 15.50 | 0.83 | 27.00 | 36.00 | 49.75 | 74.00 |
is_pclass1 True | 186.00 | 38.23 | 14.80 | 0.92 | 27.00 | 37.00 | 49.00 | 80.00 |
is_male False | is_male True | |
|---|---|---|
is_pclass1 False | 0.33 | 0.67 |
is_pclass1 True | 0.46 | 0.54 |
is_male False | is_male True | |
|---|---|---|
is_pclass1 False | 0.46 | 0.54 |
is_pclass1 True | 0.46 | 0.54 |
Variable | SMD Value |
|---|---|
Age | 0.0258 |
is_male | 0.0000 |
is_pclass1 | Mean | Standard Deviation | Count |
|---|---|---|---|
False | 0.36 | 0.48 | 186 |
True | 0.66 | 0.48 | 186 |
Est. | S.e. | z | P>|z| | [95% Conf. int.] | |
|---|---|---|---|---|---|
ATE | 0.284 | 0.056 | 5.042 | 0.000 | (0.173, 0.394) |
ATC | 0.277 | 0.064 | 4.313 | 0.000 | (0.151, 0.403) |
ATT | 0.302 | 0.057 | 5.258 | 0.000 | (0.189, 0.414) |
ATE | Average Treatment Effect |
SMD | Standardized Mean Differences |
ATT | Average Treatment Impact on the Treated |
ATC | Average Treatment Effect on the Control |
| [1] | H. Harris and S. J. Horst, “A brief guide to decisions at each step of the propensity score matching process,” Practical Assessment, Research, and Evaluation, vol. 21, no. 1, p. 4, 2019. |
| [2] | A. S. Jones, R. B. D’Agostino Jr, E. W. Gondolf, and A. Heckert, “Assessing the effect of batterer program completion on reassault using propensity scores,” Journal of Interpersonal Violence, vol. 19, no. 9, pp. 1002–1020, 2004. |
| [3] | P. R. Rosenbaum and D. B. Rubin, “The central role of the propensity score in observational studies for causal effects,” Biometrika, vol. 70, no. 1, pp. 41–55, 1983. |
| [4] | P. R. Rosenbaum and D. B. Rubin, “The bias due to incomplete matching,” Biometrics, pp. 103–116, 1985. |
| [5] | M. Caliendo and S. Kopeinig, “Some practical guidance for the implementation of propensity score matching,” Journal of economic surveys, vol. 22, no. 1, pp. 31–72, 2008. |
| [6] | X. S. Gu and P. R. Rosenbaum, “Comparison of multivariate matching methods: Structures, distances, and algorithms,” Journal of Computational and Graphical Statistics, vol. 2, no. 4, pp. 405–420, 1993. |
| [7] | D. E. Ho, K. Imai, G. King, and E. A. Stuart, “Matching as nonparametric preprocessing for reducing model dependence in parametric causal inference,” Political analysis, vol. 15, no. 3, pp. 199–236, 2007. |
| [8] | M. A. Brookhart, S. Schneeweiss, K. J. Rothman, R. J. Glynn, J. Avorn, and T. Stürmer, “Variable selection for propensity score models,” American journal of epidemiology, vol. 163, no. 12, pp. 1149–1156, 2006. |
| [9] | A. W. Steiner, J. M. Lattimer, and E. F. Brown, “The equation of state from observed masses and radii of neutron stars,” The Astrophysical Journal, vol. 722, no. 1, p. 33, 2010. |
| [10] | E. A. Stuart, “Matching methods for causal inference: A review and a look forward,” Statistical science: a review journal of the Institute of Mathematical Statistics, vol. 25, no. 1, p. 1, 2010. |
| [11] | P. C. Austin, “An introduction to propensity score methods for reducing the effects of confounding in observational studies,” Multivariate behavioral research, vol. 46, no. 3, pp. 399–424, 2011. |
| [12] | G. W. Imbens, “Nonparametric estimation of average treatment effects under exogeneity: A review,” Review of Economics and statistics, vol. 86, no. 1, pp. 4–29, 2004. |
| [13] | H. J. Schmoll, R. Souchon, S. Krege, P. Albers, J. Beyer, C. Kollmannsberger, S. Fossa, N. Skakkebaek, R. De Wit, K. Fizazi, et al., “European consensus on diagnosis and treatment of germ cell cancer: a report of the european germ cell cancer consensus group (egcccg),” Annals of Oncology, vol. 15, no. 9, pp. 1377–1399, 2004. |
| [14] | S. L. Morgan and J. J. Todd, “A diagnostic routine for the detection of consequential heterogeneity of causal effects,” Sociological Methodology, vol. 38, no. 1, pp. 231–281, 2008. |
| [15] | T. Young, L. Finn, P. E. Peppard, M. Szklo-Coxe, D. Austin, F. J. Nieto, R. Stubbs, and K. M. Hla, “Sleep disordered breathing and mortality: eighteen-year follow-up of the wisconsin sleep cohort,” Sleep, vol. 31, no. 8, pp. 1071–1078, 2008. |
| [16] | B. K. Flury and H. Riedwyl, “Standard distance in univariate and multivariate analysis,” The American Statistician, vol. 40, no. 3, pp. 249–251, 1986. |
| [17] | P. C. Austin, “Balance diagnostics for comparing the distribution of baseline covariates between treatment groups in propensity-score matched samples,” Statistics in medicine, vol. 28, no. 25, pp. 3083–3107, 2009. |
| [18] | A. Buja, D. Cook, H. Hofmann, M. Lawrence, E.-K. Lee, D. F. Swayne, and H. Wickham, “Statistical inference for exploratory data analysis and model diagnostics,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 367, no. 1906, pp. 4361–4383, 2009. |
APA Style
Collins, W., Anjela, W., Jacinta, M. (2024). Propensity Score Matching: An Application on Observational Data. American Journal of Mathematical and Computer Modelling, 9(3), 68-77. https://doi.org/10.11648/j.ajmcm.20240903.12
ACS Style
Collins, W.; Anjela, W.; Jacinta, M. Propensity Score Matching: An Application on Observational Data. Am. J. Math. Comput. Model. 2024, 9(3), 68-77. doi: 10.11648/j.ajmcm.20240903.12
AMA Style
Collins W, Anjela W, Jacinta M. Propensity Score Matching: An Application on Observational Data. Am J Math Comput Model. 2024;9(3):68-77. doi: 10.11648/j.ajmcm.20240903.12
@article{10.11648/j.ajmcm.20240903.12,
author = {Wangila Collins and Wanjala Anjela and Muindi Jacinta},
title = {Propensity Score Matching: An Application on Observational Data
},
journal = {American Journal of Mathematical and Computer Modelling},
volume = {9},
number = {3},
pages = {68-77},
doi = {10.11648/j.ajmcm.20240903.12},
url = {https://doi.org/10.11648/j.ajmcm.20240903.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ajmcm.20240903.12},
abstract = {The study aimed to determine the survival rate of first-class passengers using the Titanic dataset from Kaggle. Descriptive statistics revealed that first class passengers had way more chance to survive as compared to other classes, which underscores the role of socioeconomic status in determining chances of survival. Evaluation metrics, which assess model performance independently for male and female cohorts, shed light on gender specific projected accuracy. The analysis of propensity scores matching data for male and female passengers separately ensured that each gender category had control groups and treatments that were equally distributed. It was discovered that women had higher survival rates compared to men and these findings also identified disparities in the levels of surviving among genders. Improvements in covariate balance were indicated by post-matching statistics for both the male and female cohorts, indicating that the matching process was successful for both genders. The treatment effect estimates for male and female passengers were computed independently, and the findings showed that a number of characteristics significantly improved the survival rates for each gender group. The overall results of the study emphasized how important it is to include gender when analyzing survival outcomes using the Titanic dataset. In addition, age was suggested as an important factor whereby young people had higher chances of being saved.
},
year = {2024}
}
TY - JOUR T1 - Propensity Score Matching: An Application on Observational Data AU - Wangila Collins AU - Wanjala Anjela AU - Muindi Jacinta Y1 - 2024/12/03 PY - 2024 N1 - https://doi.org/10.11648/j.ajmcm.20240903.12 DO - 10.11648/j.ajmcm.20240903.12 T2 - American Journal of Mathematical and Computer Modelling JF - American Journal of Mathematical and Computer Modelling JO - American Journal of Mathematical and Computer Modelling SP - 68 EP - 77 PB - Science Publishing Group SN - 2578-8280 UR - https://doi.org/10.11648/j.ajmcm.20240903.12 AB - The study aimed to determine the survival rate of first-class passengers using the Titanic dataset from Kaggle. Descriptive statistics revealed that first class passengers had way more chance to survive as compared to other classes, which underscores the role of socioeconomic status in determining chances of survival. Evaluation metrics, which assess model performance independently for male and female cohorts, shed light on gender specific projected accuracy. The analysis of propensity scores matching data for male and female passengers separately ensured that each gender category had control groups and treatments that were equally distributed. It was discovered that women had higher survival rates compared to men and these findings also identified disparities in the levels of surviving among genders. Improvements in covariate balance were indicated by post-matching statistics for both the male and female cohorts, indicating that the matching process was successful for both genders. The treatment effect estimates for male and female passengers were computed independently, and the findings showed that a number of characteristics significantly improved the survival rates for each gender group. The overall results of the study emphasized how important it is to include gender when analyzing survival outcomes using the Titanic dataset. In addition, age was suggested as an important factor whereby young people had higher chances of being saved. VL - 9 IS - 3 ER -
Department of Mathematics, University of Nairobi, Nairobi, Kenya
Department of Mathematics, University of Nairobi, Nairobi, Kenya
Department of Mathematics, University of Nairobi, Nairobi, Kenya
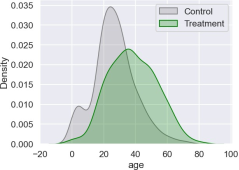
Figure 1. Treatment group comparison based on age.
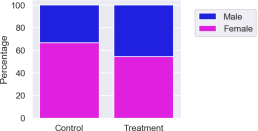
Figure 2. Gender distribution in the Titanic dataset.
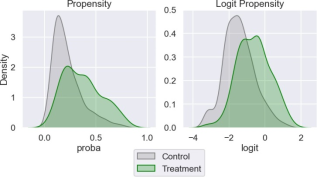
Figure 3. Propensity score and logit propensity.
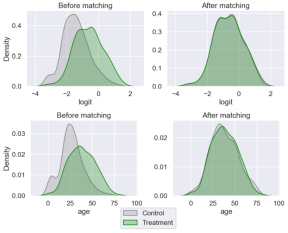
Figure 4. Control and treatment distributions before and after matching.
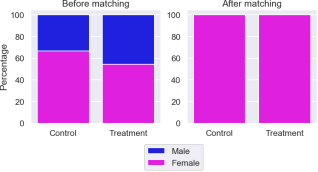
Figure 5. Bar graphs the distribution of gender before and after matching.
Information

