Neonatal mortality remains a critical public health challenge in Kenya, with a rate of 21 per 1,000 live births—well above the SDG 3.2 target. While machine learning (ML) offers potential for risk prediction, most models lack transparency and clinical interpretability, limiting their adoption in low-resource settings. This study presents an explainable AI (XAI) framework for predicting neonatal mortality using Kenya Demographic and Health Survey (KDHS) data (N = 2,000), with a focus on model accuracy, fairness, and clinical relevance. Six ML models—Logistic Regression (LR), KNN, SVM, Naïve Bayes, Random Forest, and XG-Boost—were trained and evaluated using in-sample, out-of-sample, and balanced datasets, with performance assessed via AUC, F1-score, sensitivity, specificity, and Cohen’s Kappa. To address class imbalance and enhance generalizability, synthetic oversampling and rigorous cross-validation were applied. Post-balancing, LR achieved optimal performance (AUC = 1.0, κ = 0.98, F1 = 0.987), with SVM (AUC = 0.995) and XG-Boost (AUC = 0.982) also showing higher performance. SHAP and model breakdown analyses identified Apgar scores (at 1st and 5th minutes), birth weight, maternal health, and prenatal visit frequency as key predictors. Fairness assessments across socioeconomic subgroups indicated minimal bias (DIR > 0.8). The integration of XAI enhances transparency, supports clinician trust, and enables equitable decision-making. This framework bridges the gap between predictive accuracy and clinical usability, offering a scalable tool for early intervention. Policy recommendations include embedding this XAI-enhanced model into antenatal care systems to support evidence-based decisions and accelerate progress toward neonatal survival goals in resource-limited settings.
| Published in | Biomedical Statistics and Informatics (Volume 10, Issue 3) |
| DOI | 10.11648/j.bsi.20251003.12 |
| Page(s) | 64-83 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Explainable Artificial Intelligence (XAI), Neonatal Mortality, Machine Learning, Predictive Modelling, Health Belief Model, Calibration
Study (year) | Setting/data | Model(s) | Outcome | Performance (AUC / C-index) | XAI used? | External validation? | LMIC focus? |
|---|---|---|---|---|---|---|---|
Batista et al. 2021 (BMC Pediatrics) | São Paulo, Brazil birth registry (SINASC+SIM), 2012-2017 | Gradient boosting, RF, XGB, SVM, LR | Neonatal death (≤28 days) | AUC ≈0.97 overall; with only 5 WHO variables, AUC ≈0.91 (reported by study team in talk materials | Yes—SHAP + feature importance discussed | Internal split; no true external geo-temporal validation reported | Yes |
Beluzo et al. 2020 (medRxiv) | São Paulo, Brazil (SPNeoDeath) | SVM, XGBoost, LR, RF | Neonatal death | Average AUC ≈0.96 across models (best models) | Mentions model interpretability; SHAP used in the related slide deck | Internal validation; no external cohort | Yes |
Mulagha-Maganga et al. 2024 (JHPN) | Malawi DHS 2015/16 | Survival models (e.g., parametric/Cox) | Time to death < 5y | Survival outputs (HRs); AUC not reported | No (classical covariate effects) | Not reported | Yes |
Daniel, Onyango & Sarguta 2021 (IJERPH) | Kenya (KDHS) | Bayesian spatial survival model (shared frailty) | Under-five mortality | Survival outputs (HRs/spatial effects); AUC not reported | Partial (spatial effect maps, not XAI) | Not reported | Yes |
Wanjohi & Muriithi 2020 (IJDSA) | Kenya | Regression/survival modelling of infant & child mortality covariates | Infant/child mortality | Classical fit metrics; AUC not reported | No | Not reported | Yes |
Starnes et al. 2023 (BMJ Open) | Migori County, Kenya (household survey) | Regression models (risk factors) | Child mortality | Effect estimates; no AUC (not an ML study) | No | Not applicable | Yes |
Kimani-Murage et al. 2014 (Health & Place) | Kenya (urban slum vs non-slum) | Time-trend and regression analyses | Child mortality trends | No AUC | No | Not applicable | Yes |
Otieno, Kosgei & Owuor 2023 (Biomed. Stats & Informatics) | Kenya (KDHS 2014) | Multilevel models | Child mortality determinants | Fit stats: AUC not reported | No | Not reported | Yes |
Mwambire & Orowe 2021 (Applied Mathematical Sciences) | Kenya (KDHS) | Multilevel modelling | Child mortality | Fit stats: AUC not reported | No | Not reported | Yes |
Oleribe et al. 2019 (IJGM) | Sub-Saharan Africa (review/commentary) | — | Health-system challenges | — | — | — | Yes (context) |
Variables | N | Mean | SD | SE of Mean | IQR | Skewness | Kurtosis |
|---|---|---|---|---|---|---|---|
Maternal Age | 2000 | 29.9355 | 8.6157678 | 0.192654426 | 14 | 0.000935439 | -1.16442103 |
Prenatal Visits | 2000 | 6.005 | 2.4857724 | 0.055583561 | 4 | 0.384916833 | 0.04986876 |
Birth Weight (kg) | 2000 | 2.99118 | 0.5910733 | 0.0132168 | 0.78 | -0.013783963 | -0.00415725 |
Gestational Age weeks | 2000 | 38.005 | 3.0084049 | 0.067269979 | 4 | 0.006338025 | 0.12995457 |
Maternal Health Score | 2000 | 5.45395 | 2.5892852 | 0.057898177 | 4.6425 | 0.048540512 | -1.21172686 |
Socioeconomic status | 2000 | 2.2215 | 1.0295473 | 0.023021378 | 2 | 0.315363781 | -1.07189549 |
Delivery Method | 2000 | 0.31 | 0.4626089 | 0.01034425 | 1 | 0.822250442 | -1.32523044 |
Multiple Birth | 2000 | 0.05 | 0.2179995 | 0.004874616 | 0 | 4.132583293 | 15.09333702 |
Maternal Nutrition Score | 2000 | 5.514095 | 2.5991653 | 0.058119102 | 4.55 | -0.022769403 | -1.22021257 |
Maternal Chronic Conditions | 2000 | 0.2155 | 0.4112716 | 0.009196312 | 0 | 1.384898887 | -0.08213821 |
Skilled Birth Attendant | 2000 | 0.853 | 0.3541945 | 0.007920029 | 0 | -1.995250504 | 1.98300658 |
Maternal Education Level | 2000 | 2.505 | 0.9329578 | 0.02086157 | 1 | 0.007646716 | -0.86898595 |
Smoking During Pregnancy | 2000 | 0.097 | 0.2960318 | 0.006619472 | 0 | 2.725406018 | 5.43327023 |
Alcohol Use During Pregnancy | 2000 | 0.08 | 0.271361 | 0.006067817 | 0 | 3.098605518 | 7.60896412 |
Environmental Exposure | 2000 | 0.1525 | 0.3595948 | 0.008040784 | 0 | 1.934665737 | 1.74467519 |
Apgar Score 1min | 2000 | 4.89405 | 2.8732921 | 0.064248765 | 5 | 0.07152707 | -1.19034715 |
Apgar Score 5min | 2000 | 4.9144 | 2.8695435 | 0.064164943 | 4.8 | 0.037802853 | -1.18149798 |
NICU Admission | 2000 | 0.194 | 0.3955278 | 0.00884427 | 0 | 1.548848528 | 0.39933009 |
History of Pregnancy Complications | 2000 | 0.2035 | 0.4027019 | 0.009004689 | 0 | 1.474027234 | 0.17292821 |
Partner Support Score | 2000 | 3.1005 | 1.1193866 | 0.025030244 | 2 | -0.175016446 | -0.71442251 |
Maternal Depression Score | 2000 | 5.03071 | 2.9314471 | 0.065549149 | 5.17 | -0.004802599 | -1.22901243 |
Distance to Health Facility (km) | 2000 | 9.8086 | 9.4969623 | 0.212358532 | 10.8 | 1.991719694 | 6.47230171 |
Household Size | 2000 | 4.988 | 2.2305478 | 0.049876566 | 3 | 0.413860007 | 0.09036552 |
Characteristic | N | Overall | Yes | 95% CI | No | 95% CI | p-value2 |
|---|---|---|---|---|---|---|---|
N = 2,0001 | N = 6001 | N = 1,4001 | |||||
Maternal Age | 2,000 | 29.94 (8.62) | 31.45 (8.60) | 31, 32 | 29.29 (8.54) | 29, 30 | <0.001 |
Prenatal Visits | 2,000 | 6.01 (2.49) | 5.47 (2.27) | 5.3, 5.6 | 6.24 (2.54) | 6.1, 6.4 | <0.001 |
Birth Weight kg | 2,000 | 2.99 (0.59) | 2.86 (0.59) | 2.8, 2.9 | 3.05 (0.58) | 3.0, 3.1 | <0.001 |
Gestational Age weeks | 2,000 | 38.01 (3.01) | 37.05 (2.94) | 37, 37 | 38.42 (2.95) | 38, 39 | <0.001 |
Maternal Health Score | 2,000 | 5.45 (2.59) | 4.53 (2.37) | 4.3, 4.7 | 5.85 (2.58) | 5.7, 6.0 | <0.001 |
Socioeconomic Status | 2,000 | <0.001 | |||||
Low | 608 (30%) | 201 (34%) | 30%, 37% | 407 (29%) | 27%, 32% | ||
Lower Middle | 620 (31%) | 212 (35%) | 32%, 39% | 408 (29%) | 27%, 32% | ||
Upper Middle | 493 (25%) | 133 (22%) | 19%, 26% | 360 (26%) | 23%, 28% | ||
High | 279 (14%) | 54 (9.0%) | 6.9%, 12% | 225 (16%) | 14%, 18% | ||
Delivery Method | 2,000 | 620 (31%) | 206 (34%) | 31%, 38% | 414 (30%) | 27%, 32% | 0.035 |
Multiple Birth | 2,000 | 100 (5.0%) | 36 (6.0%) | 4.3%, 8.3% | 64 (4.6%) | 3.6%, 5.8% | 0.2 |
Maternal Nutrition Score | 2,000 | 5.51 (2.60) | 4.91 (2.58) | 4.7, 5.1 | 5.77 (2.56) | 5.6, 5.9 | <0.001 |
Maternal Chronic Conditions | 2,000 | 431 (22%) | 161 (27%) | 23%, 31% | 270 (19%) | 17%, 21% | <0.001 |
Skilled Birth Attendant | 2,000 | 1,706 (85%) | 486 (81%) | 78%, 84% | 1,220 (87%) | 85%, 89% | <0.001 |
Maternal Education Level | 2,000 | 0.068 | |||||
No Education | 304 (15%) | 104 (17%) | 14%, 21% | 200 (14%) | 13%, 16% | ||
Primary | 698 (35%) | 221 (37%) | 33%, 41% | 477 (34%) | 32%, 37% | ||
Secondary | 682 (34%) | 194 (32%) | 29%, 36% | 488 (35%) | 32%, 37% | ||
Tertiary | 316 (16%) | 81 (14%) | 11%, 17% | 235 (17%) | 15%, 19% | ||
Smoking During Pregnancy | 2,000 | 194 (9.7%) | 86 (14%) | 12%, 17% | 108 (7.7%) | 6.4%, 9.3% | <0.001 |
Alcohol Use During Pregnancy | 2,000 | 160 (8.0%) | 62 (10%) | 8.1%, 13% | 98 (7.0%) | 5.7%, 8.5% | 0.012 |
Environmental Exposure | 2,000 | 305 (15%) | 115 (19%) | 16%, 23% | 190 (14%) | 12%, 16% | 0.001 |
Apgar_Score_1min | 2,000 | 4.89 (2.87) | 3.58 (2.59) | 3.4, 3.8 | 5.46 (2.81) | 5.3, 5.6 | <0.001 |
Apgar_Score_5min | 2,000 | 4.91 (2.87) | 3.24 (2.31) | 3.1, 3.4 | 5.63 (2.79) | 5.5, 5.8 | <0.001 |
NICU Admission | 2,000 | 388 (19%) | 159 (27%) | 23%, 30% | 229 (16%) | 14%, 18% | <0.001 |
History of Pregnancy Complications | 2,000 | 407 (20%) | 145 (24%) | 21%, 28% | 262 (19%) | 17%, 21% | 0.006 |
Partner Support Score | 2,000 | 0.005 | |||||
Not supportive at all | 186 (9.3%) | 64 (11%) | 8.4%, 13% | 122 (8.7%) | 7.3%, 10% | ||
Slightly Supportive | 407 (20%) | 139 (23%) | 20%, 27% | 268 (19%) | 17%, 21% | ||
Moderately Supportive | 624 (31%) | 199 (33%) | 29%, 37% | 425 (30%) | 28%, 33% | ||
Supportive | 586 (29%) | 152 (25%) | 22%, 29% | 434 (31%) | 29%, 34% | ||
Very Supportive | 197 (9.9%) | 46 (7.7%) | 5.7%, 10% | 151 (11%) | 9.2%, 13% | ||
Maternal Depression Score | 2,000 | 5.03 (2.93) | 6.24 (2.79) | 6.0, 6.5 | 4.51 (2.84) | 4.4, 4.7 | <0.001 |
Distance to Health Facility (km) | 2,000 | 9.81 (9.50) | 12.09 (11.14) | 11, 13 | 8.83 (8.52) | 8.4, 9.3 | <0.001 |
Type of Health Facility | 2,000 | <0.001 | |||||
private | 475 (24%) | 122 (20%) | 17%, 24% | 353 (25%) | 23%, 28% | ||
public | 1,240 (62%) | 368 (61%) | 57%, 65% | 872 (62%) | 60%, 65% | ||
Rural clinic | 285 (14%) | 110 (18%) | 15%, 22% | 175 (13%) | 11%, 14% | ||
Household Size | 2,000 | 4.99 (2.23) | 5.21 (2.22) | 5.0, 5.4 | 4.89 (2.23) | 4.8, 5.0 | 0.003 |
Sample | Mortality | Total | |
|---|---|---|---|
Yes | No | ||
Test | 190 | 410 | 600 |
31.7% | 68.3% | 100% | |
31.7% | 29.3% | 30% | |
Train | 410 | 990 | 1400 |
29.3% | 70.7% | 100% | |
68.3% | 70.7% | 70% | |
Total | 600 | 1400 | 2000 |
30% | 70% | 100% | |
100% | 100% | 100% | |
Sample | Model | Sensitivity | Specificity | Precision | F1_Score | Recall | NPV | PPV | Balanced Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|---|
In-sample Model Performance | LR Model | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
SVM Model | 0.4820 | 0.9840 | 0.9270 | 0.6350 | 0.4820 | 0.8160 | 0.9270 | 0.7330 | 0.5400 | |
KNN-Model | 0.9600 | 0.9960 | 0.9910 | 0.9750 | 0.9600 | 0.9830 | 0.9910 | 0.9780 | 0.9650 | |
Naïve Bayes | 0.6470 | 0.9320 | 0.8040 | 0.7170 | 0.6470 | 0.8600 | 0.8040 | 0.7900 | 0.6130 | |
Random Forest | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
XG-Boost | 0.9200 | 0.9940 | 0.9860 | 0.9520 | 0.9200 | 0.9670 | 0.9860 | 0.9570 | 0.9320 | |
Out-of-Sample Model Performance | LR Model | 0.9800 | 0.9970 | 0.9930 | 0.9870 | 0.9800 | 0.9910 | 0.9930 | 0.9890 | 0.9810 |
SVM Model | 0.3130 | 0.9690 | 0.8100 | 0.4520 | 0.3130 | 0.7670 | 0.8100 | 0.6410 | 0.3420 | |
KNN-Model | 0.8800 | 0.9910 | 0.9780 | 0.9260 | 0.8800 | 0.9510 | 0.9780 | 0.9360 | 0.8970 | |
Naïve Bayes | 0.5530 | 0.9200 | 0.7480 | 0.6360 | 0.5530 | 0.8280 | 0.7480 | 0.7370 | 0.5110 | |
Random Forest | 0.5470 | 0.9510 | 0.8280 | 0.6590 | 0.5470 | 0.8300 | 0.8280 | 0.7490 | 0.5520 | |
XG-Boost | 0.8270 | 0.9630 | 0.9050 | 0.8640 | 0.8270 | 0.9280 | 0.9050 | 0.8950 | 0.8100 |
Model | Sensitivity | Specificity | Precision | Recall | F1-Score | NPV | PPV | Balanced Accuracy | Kappa |
|---|---|---|---|---|---|---|---|---|---|
LR Model | 0.97400 | 1.00000 | 1.00000 | 0.97400 | 0.98700 | 0.98800 | 1.00000 | 0.98700 | 0.98100 |
SVM Model | 0.88900 | 0.99300 | 0.98300 | 0.88900 | 0.93400 | 0.95100 | 0.98300 | 0.94100 | 0.90500 |
KNN-Model | 0.73200 | 0.77300 | 0.59900 | 0.73200 | 0.65900 | 0.86100 | 0.59900 | 0.75200 | 0.47600 |
Naïve Bayes | 0.82600 | 0.87600 | 0.75500 | 0.82600 | 0.78900 | 0.91600 | 0.75500 | 0.85100 | 0.68500 |
Random Forest | 0.56300 | 0.99500 | 0.98200 | 0.56300 | 0.71600 | 0.83100 | 0.98200 | 0.77900 | 0.63000 |
XG-Boost | 0.85300 | 0.97100 | 0.93100 | 0.85300 | 0.89000 | 0.93400 | 0.93100 | 0.91200 | 0.84200 |
AUC | Area Under the Curve |
CI | Confidence Interval |
DHS | Demographic and Health Survey |
KDHS | Kenya Demographic and Health Survey |
KNN | K-Nearest Neighbours |
LMICs | Low- and Middle-Income Countries |
ML | Machine Learning |
NICU | Neonatal Intensive Care Unit |
PPV | Positive Predictive Value |
NPV | Negative Predictive Value |
SDG | Sustainable Development Goal |
XAI | Explainable Artificial Intelligence |
| [1] | Batista, A. F. M., Diniz, C. S. G., Bonilha, E. A., Kawachi, I., & Chiavegatto Filho, A. D. P. (2021). Neonatal mortality prediction with routinely collected data: a machine learning approach. BMC Pediatrics, 21(1). |
| [2] | Starnes, J. R., Rogers, A., Wamae, J., Okoth, V., Mudhune, S. A., Omondi, A., Were, V., Awino, D. B., Lefebvre, C. H., Yap, S., Odhong, T. O., Vill, B., Were, L., & Wamai, R. (2023). Childhood mortality and associated factors in Migori County, Kenya: evidence from a cross-sectional survey. BMJ Open, 13(8), e074056. |
| [3] | Mulagha-Maganga, A., Kazembe, L., & Ndiragu, M. (2024). Modelling time to death for under-five children in Malawi using 2015/16 Demographic and Health Survey: a survival analysis. Journal of Health, Population and Nutrition, 43(1). |
| [4] | Oleribe, O. E., Momoh, J., Uzochukwu, B. S., Mbofana, F., Adebiyi, A., Barbera, T., Williams, R., & Taylor Robinson, S. D. (2019). Identifying key challenges facing healthcare systems in Africa and potential solutions. International Journal of General Medicine, 12(1), 395-403. |
| [5] | Muthii Wanjohi, S., & Mwangi Muriithi, D. (2020). Modelling Covariates of Infant and Child Mortality in Kenya. International Journal of Data Science and Analysis, 6(3), 90. |
| [6] | Kimani-Murage, E. W., Fotso, J. C., Egondi, T., Abuya, B., Elungata, P., Ziraba, A. K., Kabiru, C. W., & Madise, N. (2014). Trends in childhood mortality in Kenya: The urban advantage has seemingly been wiped out. Health & Place, 29, 95-103. |
| [7] | Daniel, K., Onyango, N. O., & Sarguta, R. J. (2021). A Spatial Survival Model for Risk Factors of Under-Five Child Mortality in Kenya. International Journal of Environmental Research and Public Health, 19(1), 399. |
| [8] | Otieno, O., Kosgei, M., & Onyango Owuor, N. (2023). On Multilevel Modeling of Child Mortality with Application to KDHS Data 2014. Biomedical Statistics and Informatics. |
| [9] | Beluzo, C. E., Alves, L. C., Silva, E., Bresan, R., Arruda, N., & Carvalho, T. (2020). Machine Learning to Predict Neonatal Mortality Using Public Health Data from São Paulo - Brazil. MedRxiv (Cold Spring Harbor Laboratory). |
| [10] | Muriithi, D. K., Lumumba, V. W., Awe, O. O., & Muriithi, D. M. (2025). An Explainable Artificial Intelligence Models for Predicting Malaria Risk in Kenya. European Journal of Artificial Intelligence and Machine Learning, 4(1), 1-8. |
| [11] | Otieno, O., Kosgei, M., & Onyango Owuor, N. (2023). Statistical Modelling and Evaluation of Determinants of Child Mortality in Nyanza, Kenya. Biomedical Statistics and Informatics. |
| [12] | Mutunga, C. J. (2007). Environmental Determinants of Child Mortality in Kenya. World Institute for Development Economics Research. |
| [13] | Mwambire, L. R., & Orowe, I. (2021). Multilevel modelling of factors affecting child mortality in Kenya. Applied Mathematical Sciences, 15(2), 79-94. |
| [14] | Anny Leema, A., Balakrishnan, P., Akula, V. K., Ramacharan, S., & Jothiaruna, N. (2025). Smart Object Integration in Neonatal Health: Leveraging RFID and Explainable AI for Mortality Risk Prediction. Cognitive Science and Technology, 411-427. |
| [15] | Rane, J., Kaya, Ö., Mallick, S. K., & Rane, N. L. (2024). Enhancing black-box models: Advances in explainable artificial intelligence for ethical decision-making. |
| [16] | Hassan, M., Kushniruk, A., & Borycki, E. (2024). Barriers and Facilitators of Artificial Intelligence Adoption in Healthcare: A Scoping Review (Preprint). JMIR Human Factors, 11, e48633-e48633. |
| [17] | Njenga, J. K., & Kipchirchir, I. C. (2024). Modelling Mortality in Kenya. Asian Research Journal of Mathematics, 20(1), 1-15. |
| [18] | Ali, S., Abuhmed, T., El-Sappagh, S., Muhammad, K., Alonso-Moral, J. M., Confalonieri, R., Guidotti, R., Ser, J. D., Díaz-Rodríguez, N., & Herrera, F. (2023). Explainable Artificial Intelligence (XAI): What we know and what is left to attain Trustworthy Artificial Intelligence. Information Fusion, 99(101805), 101805. sciencedirect. |
| [19] | O’Sullivan, C., Tsai, D. H.-T., Wu, I. C.-Y., Boselli, E., Hughes, C., Padmanabhan, D., & Hsia, Y. (2023). Machine learning applications on neonatal sepsis treatment: a scoping review. 23(1). |
| [20] | Shaw, P., Pachpor, K., & Sankaranarayanan, S. (2023). Explainable AI Enabled Infant Mortality Prediction Based on Neonatal Sepsis. Computer Systems Science and Engineering, 44(1), 311-325. |
| [21] | Grover, V., & Dogra, M. (2024). Challenges and Limitations of Explainable AI in Healthcare. Advances in Healthcare Information Systems and Administration Book Series, 72-85. |
| [22] | Rees, C. A., Kisenge, R., Godfrey, E., Ideh, R. C., Kamara, J., Coleman-Nekar, Y.-J. G., Samma, A., Manji, H. K., Sudfeld, C. R., Westbrook, A. L., Niescierenko, M., Morris, C. R., Florin, T. A., Whitney, C. G., Manji, K. P., Duggan, C. P., & Rishikesan Kamaleswaran. (2025). Machine learning approaches to identify neonates and young children at risk for postdischarge mortality in Dar es Salaam, Tanzania and Monrovia, Liberia. PubMed, 9(1). |
| [23] | Kimeu, C. (2024, December 6). How AI monitoring is cutting stillbirths and neonatal deaths in a clinic in Malawi. The Guardian; The Guardian. |
| [24] | Davis, S. E., Embí, P. J., & Matheny, M. E. (2024). Sustainable deployment of clinical prediction tools—a 360° approach to model maintenance. Journal of the American Medical Informatics Association, 31(5), 1195-1198. |
| [25] | Youssef, A., Pencina, M., Thakur, A., Zhu, T., Clifton, D., & Shah, N. H. (2023). External validation of AI models in health should be replaced with recurring local validation. Nature Medicine, 29(11), 2686-2687. |
| [26] | Mangold, C., Zoretic, S., Thallapureddy, K., Moreira, A., Chorath, K., & Moreira, A. (2021). Machine Learning Models for Predicting Neonatal Mortality: A Systematic Review. Neonatology, 118(4), 394-405. |
| [27] | Davoudi, A., Chae, S., Evans, L., Sridharan, S., Song, J., Bowles, K. H., McDonald, M. V., & Topaz, M. (2024). Fairness gaps in Machine learning models for hospitalisation and emergency department visit risk prediction in home healthcare patients with heart failure. International Journal of Medical Informatics, 191, 105534-105534. |
| [28] | Ponnusamy, S., & Gupta, P. (2024). Scalable Data Partitioning Techniques for Distributed Data Processing in Cloud Environments: A Review. IEEE Access, 1-1. |
| [29] | Bouke, M. A., & Abdullah, A. (2023). An Empirical Study of Pattern Leakage Impact During Data Preprocessing On Machine Learning-Based Intrusion Detection Models Reliability. Expert Systems with Applications, 230, 120715-120715. |
| [30] | Dobrev, S., Narayanan, L., Opatrny, J., & Pankratov, D. (2024). Exploration of High-Dimensional Grids by Finite State Machines. Algorithmica, 86(5), 1700-1729. |
| [31] | Mahlknecht, G., Dignös, A., & Gamper, J. (2015). Efficient Computation of Parsimonious Temporal Aggregation. Lecture Notes in Computer Science, 320-333. |
| [32] | Domínguez-Almendros, S., Benítez-Parejo, N., & Gonzalez-Ramirez, A. R. (2011). Logistic regression models. Allergologia et Immunopathologia, 39(5), 295-305. |
| [33] | Zhang, Z. (2016). Introduction to Machine learning: k-nearest Neighbors. Annals of Translational Medicine, 4(11), 218-218. |
| [34] | Cunningham, P., & Delany, S. J. (2021). k-Nearest Neighbour Classifiers - A Tutorial. ACM Computing Surveys, 54(6), 1-25. |
| [35] | Peterson, L. (2009). K-nearest neighbor. Scholarpedia, 4(2), 1883. |
| [36] | Liang, J.-D., Ping, X.-O., Tseng, Y.-J., Huang, G.-T., Lai, F., & Yang, P.-M. (2014). Recurrence predictive models for patients with hepatocellular carcinoma after radiofrequency ablation using support vector machines with feature selection methods. Computer Methods and Programs in Biomedicine, 117(3), 425-434. |
| [37] | Lumumba, V., Kiprotich, D., Mpaine, M., Makena, N., & Kavita, M. (2024). Comparative Analysis of Cross-Validation Techniques: LOOCV, K-folds Cross-Validation, and Repeated K-folds Cross-Validation in Machine Learning Models. American Journal of Theoretical and Applied Statistics, 13(5), 127-137. |
| [38] | Lumumba, V. W., Wanjuki, T. M., & Njoroge, E. W. (2025). Evaluating the Performance of Ensemble and Single Classifiers with Explainable Artificial Intelligence (XAI) on Hypertension Risk Prediction. Computational Intelligence and Machine Learning, 6(1). |
| [39] | Hassija, V., Chamola, V., Mahapatra, A., Singal, A., Goel, D., Huang, K., Scardapane, S., Spinelli, I., Mahmud, M., & Hussain, A. (2023). Interpreting Black-Box Models: a Review on Explainable Artificial Intelligence. Cognitive Computation, 16(1), 45-74. |
APA Style
Lumumba, V. W., Muriithi, D. K., Njoroge, E. W., Langat, A. K., Mwebesa, E., et al. (2025). An Explainable AI Framework for Neonatal Mortality Risk Prediction in Kenya: Enhancing Clinical Decisions with Machine Learning. Biomedical Statistics and Informatics, 10(3), 64-83. https://doi.org/10.11648/j.bsi.20251003.12
ACS Style
Lumumba, V. W.; Muriithi, D. K.; Njoroge, E. W.; Langat, A. K.; Mwebesa, E., et al. An Explainable AI Framework for Neonatal Mortality Risk Prediction in Kenya: Enhancing Clinical Decisions with Machine Learning. Biomed. Stat. Inform. 2025, 10(3), 64-83. doi: 10.11648/j.bsi.20251003.12
AMA Style
Lumumba VW, Muriithi DK, Njoroge EW, Langat AK, Mwebesa E, et al. An Explainable AI Framework for Neonatal Mortality Risk Prediction in Kenya: Enhancing Clinical Decisions with Machine Learning. Biomed Stat Inform. 2025;10(3):64-83. doi: 10.11648/j.bsi.20251003.12
@article{10.11648/j.bsi.20251003.12,
author = {Victor Wandera Lumumba and Dennis Kariuki Muriithi and Elizabeth Wambui Njoroge and Amos Kipkorir Langat and Edson Mwebesa and Maureen Ambasa Wanyama},
title = {An Explainable AI Framework for Neonatal Mortality Risk Prediction in Kenya: Enhancing Clinical Decisions with Machine Learning
},
journal = {Biomedical Statistics and Informatics},
volume = {10},
number = {3},
pages = {64-83},
doi = {10.11648/j.bsi.20251003.12},
url = {https://doi.org/10.11648/j.bsi.20251003.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.bsi.20251003.12},
abstract = {Neonatal mortality remains a critical public health challenge in Kenya, with a rate of 21 per 1,000 live births—well above the SDG 3.2 target. While machine learning (ML) offers potential for risk prediction, most models lack transparency and clinical interpretability, limiting their adoption in low-resource settings. This study presents an explainable AI (XAI) framework for predicting neonatal mortality using Kenya Demographic and Health Survey (KDHS) data (N = 2,000), with a focus on model accuracy, fairness, and clinical relevance. Six ML models—Logistic Regression (LR), KNN, SVM, Naïve Bayes, Random Forest, and XG-Boost—were trained and evaluated using in-sample, out-of-sample, and balanced datasets, with performance assessed via AUC, F1-score, sensitivity, specificity, and Cohen’s Kappa. To address class imbalance and enhance generalizability, synthetic oversampling and rigorous cross-validation were applied. Post-balancing, LR achieved optimal performance (AUC = 1.0, κ = 0.98, F1 = 0.987), with SVM (AUC = 0.995) and XG-Boost (AUC = 0.982) also showing higher performance. SHAP and model breakdown analyses identified Apgar scores (at 1st and 5th minutes), birth weight, maternal health, and prenatal visit frequency as key predictors. Fairness assessments across socioeconomic subgroups indicated minimal bias (DIR > 0.8). The integration of XAI enhances transparency, supports clinician trust, and enables equitable decision-making. This framework bridges the gap between predictive accuracy and clinical usability, offering a scalable tool for early intervention. Policy recommendations include embedding this XAI-enhanced model into antenatal care systems to support evidence-based decisions and accelerate progress toward neonatal survival goals in resource-limited settings.
},
year = {2025}
}
TY - JOUR T1 - An Explainable AI Framework for Neonatal Mortality Risk Prediction in Kenya: Enhancing Clinical Decisions with Machine Learning AU - Victor Wandera Lumumba AU - Dennis Kariuki Muriithi AU - Elizabeth Wambui Njoroge AU - Amos Kipkorir Langat AU - Edson Mwebesa AU - Maureen Ambasa Wanyama Y1 - 2025/09/30 PY - 2025 N1 - https://doi.org/10.11648/j.bsi.20251003.12 DO - 10.11648/j.bsi.20251003.12 T2 - Biomedical Statistics and Informatics JF - Biomedical Statistics and Informatics JO - Biomedical Statistics and Informatics SP - 64 EP - 83 PB - Science Publishing Group SN - 2578-8728 UR - https://doi.org/10.11648/j.bsi.20251003.12 AB - Neonatal mortality remains a critical public health challenge in Kenya, with a rate of 21 per 1,000 live births—well above the SDG 3.2 target. While machine learning (ML) offers potential for risk prediction, most models lack transparency and clinical interpretability, limiting their adoption in low-resource settings. This study presents an explainable AI (XAI) framework for predicting neonatal mortality using Kenya Demographic and Health Survey (KDHS) data (N = 2,000), with a focus on model accuracy, fairness, and clinical relevance. Six ML models—Logistic Regression (LR), KNN, SVM, Naïve Bayes, Random Forest, and XG-Boost—were trained and evaluated using in-sample, out-of-sample, and balanced datasets, with performance assessed via AUC, F1-score, sensitivity, specificity, and Cohen’s Kappa. To address class imbalance and enhance generalizability, synthetic oversampling and rigorous cross-validation were applied. Post-balancing, LR achieved optimal performance (AUC = 1.0, κ = 0.98, F1 = 0.987), with SVM (AUC = 0.995) and XG-Boost (AUC = 0.982) also showing higher performance. SHAP and model breakdown analyses identified Apgar scores (at 1st and 5th minutes), birth weight, maternal health, and prenatal visit frequency as key predictors. Fairness assessments across socioeconomic subgroups indicated minimal bias (DIR > 0.8). The integration of XAI enhances transparency, supports clinician trust, and enables equitable decision-making. This framework bridges the gap between predictive accuracy and clinical usability, offering a scalable tool for early intervention. Policy recommendations include embedding this XAI-enhanced model into antenatal care systems to support evidence-based decisions and accelerate progress toward neonatal survival goals in resource-limited settings. VL - 10 IS - 3 ER -
Department of Physical Science, Chuka University, Chuka, Kenya
Center for Data Analytics and Modelling, Chuka University, Chuka, Kenya
Department of Physical Science, Chuka University, Chuka, Kenya
Department of Statistics and Actuarial Sciences, Jomo Kenyatta University of Agriculture and Technology, Nairobi, Kenya
Department of Mathematics, Muni University, Arua, Uganda
Department of Public Health, Medwise Solutions Consultancy Limited, Nairobi, Kenya
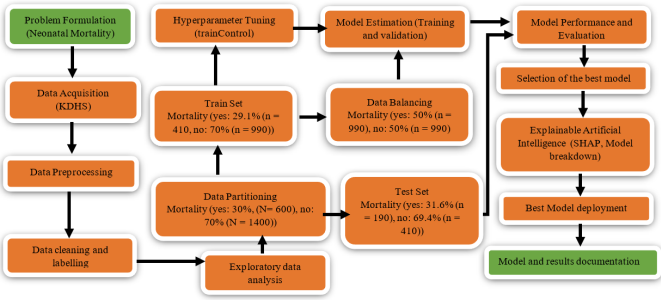
Figure 1. Machine Learning Modelling Pipeline.
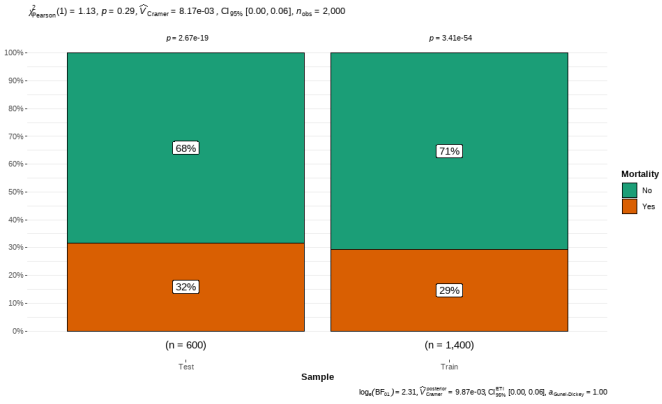
Figure 2. Testing the Case Proportion Equality.
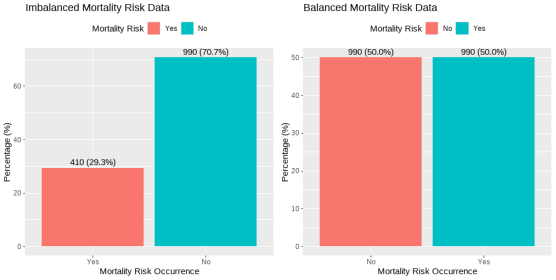
Figure 3. Imbalanced and Balanced Mortality Risk Occurrences.
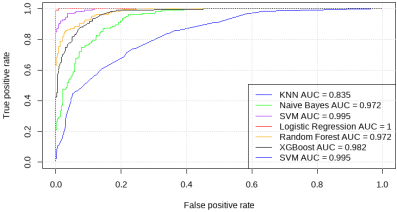
Figure 4. Receiver Operating Characteristics.

Figure 5. Models Breakdown Profiles for Best Performing Models.
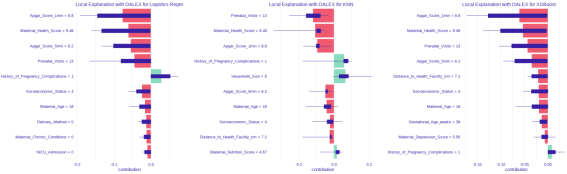
Figure 6. SHapley Additive exPlanations for the Best Performing Models.
Information

