Crack detection in pavements is a critical task for infrastructure maintenance, but it often requires extensive manual labeling of training samples, which is both time-consuming and labor-intensive. To address this challenge, this paper proposes a semi-supervised learning approach based on a DenseNet classification model to detect pavement cracks more efficiently. The primary objective is to leverage a small set of labeled samples to improve the model's performance by incorporating a large number of unlabeled samples through semi-supervised learning. This method enhances the DenseNet model's ability to generalize by iteratively learning from new unlabeled datasets. As a result, the proposed approach not only reduces the need for extensive manual labeling but also mitigates issues related to label inconsistency and errors in the original labels. The experimental results demonstrate that the semi-supervised DenseNet model achieves a prediction precision of 96.77% and a recall of 94.17%, with an F1 score of 95.45% and an Intersectidn over Union (IoU) of 91.30%. These metrics highlight the model's high accuracy and effectiveness in crack detection. The proposed method not only improves label quality and model performance but also offers practical value for engineering applications in the field of pavement maintenance, making it a valuable tool for infrastructure management.
| Published in | Engineering and Applied Sciences (Volume 9, Issue 4) |
| DOI | 10.11648/j.eas.20240904.13 |
| Page(s) | 69-82 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Crack Detection, Convolutional Neural Network (CNN), Semi-Supervised Learning, Pseudo-Labelling
Symbol | Description |
|---|---|
| Initial training set |
| The network model used, |
| Unlabeled dataset |
| Pseudo labeled dataset |
| The dataset obtained by replacing the label with the wrongly labeled sample |
| The enhanced training set consist of initial training set and wrongly labeled sample dataset |
| Unlabeled dataset generated after the training set is unlabeled |
| The training set obtained by re-labeling the training set |
| Filter the labels of the training set |
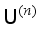 ), and then the labeled dataset is used as the training set to make the model learn. The trained model is used to label the originally unlabeled samples (
), and then the labeled dataset is used as the training set to make the model learn. The trained model is used to label the originally unlabeled samples ( 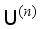 ) again (Figure 2). The results before and after labeling are not necessarily the same. How to correct these deviations is important to improve the performance of the model. It is necessary to replace or delete the inconsistent labels in the training set, so that the model can achieve consistent stability for the training set.
) again (Figure 2). The results before and after labeling are not necessarily the same. How to correct these deviations is important to improve the performance of the model. It is necessary to replace or delete the inconsistent labels in the training set, so that the model can achieve consistent stability for the training set. 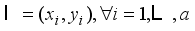 be the initial training sets of road crack images,
be the initial training sets of road crack images, 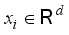 ,
, 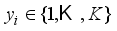 . There are two kinds of labels: background and crack. Assuming that the background label has two sequences and the crack label has only one sequence, thus there are three labels: background 1, background 2 and crack 1 (
. There are two kinds of labels: background and crack. Assuming that the background label has two sequences and the crack label has only one sequence, thus there are three labels: background 1, background 2 and crack 1 ( 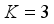 ), and each label contains a small number of samples.
), and each label contains a small number of samples. 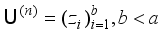 is given (
is given ( 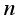 is the batch of the sample set), which belongs to the same group as
is the batch of the sample set), which belongs to the same group as 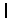 , and all of them are related datasets containing pavement crack images, and the number of samples of
, and all of them are related datasets containing pavement crack images, and the number of samples of 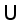 is significantly greater than
is significantly greater than 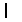 .
. 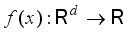 , for a certain point
, for a certain point 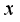 , the prediction probability distribution is SoftMax:
, the prediction probability distribution is SoftMax: 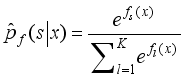 (1)
(1) 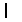 to train the model
to train the model 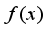 to get the initial model
to get the initial model 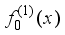 . The initial model
. The initial model 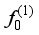 is used to pseudo label all the samples in the first batch of the originally unlabeled sample set
is used to pseudo label all the samples in the first batch of the originally unlabeled sample set 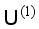 to obtain the labeled sample set
to obtain the labeled sample set 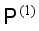 ;
; 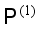 are screened out, and are replaced with new correct class sequence labels to create a subset
are screened out, and are replaced with new correct class sequence labels to create a subset 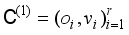 , (
, ( 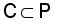 ),
), 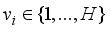 . For example, suppose that the sample labels of the initial training set corresponding to the model include: background 1, background 2, and crack 1, then in subset
. For example, suppose that the sample labels of the initial training set corresponding to the model include: background 1, background 2, and crack 1, then in subset 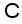 , all crack samples that were wrongly labeled as background 1 are labeled as crack 2, all crack samples that were wrongly labeled as background 2 are labeled as crack 3, and all background samples that were wrongly labeled as crack 1 are labeled as background 3, otherwise, no new class label will be added.
, all crack samples that were wrongly labeled as background 1 are labeled as crack 2, all crack samples that were wrongly labeled as background 2 are labeled as crack 3, and all background samples that were wrongly labeled as crack 1 are labeled as background 3, otherwise, no new class label will be added. 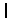 and the sample set
and the sample set 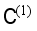 of the replacement label are combined to form a new sample set
of the replacement label are combined to form a new sample set 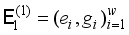 ,
, 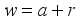 ,
, 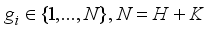 . The specific process is shown in Figure 2.
. The specific process is shown in Figure 2. 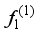 is trained by minimizing the cross-entropy loss of the enhanced training set
is trained by minimizing the cross-entropy loss of the enhanced training set 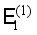 . Discard the labels in the enhanced training set
. Discard the labels in the enhanced training set 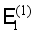 to generate the unlabeled sample set
to generate the unlabeled sample set 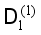 ; all the samples in the
; all the samples in the 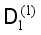 are predicted by the model
are predicted by the model 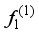 , and the results are used as the label of samples to obtain a new training set
, and the results are used as the label of samples to obtain a new training set 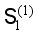 ;
; 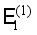 with
with 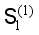 , filter the samples of different labels, delete the samples with the original label as the background and the new label as the background, and get the updated training set
, filter the samples of different labels, delete the samples with the original label as the background and the new label as the background, and get the updated training set 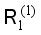 . The specific process is shown in Figure 5;
. The specific process is shown in Figure 5; 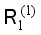 as the enhanced training set, replace
as the enhanced training set, replace 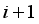 with
with 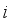 , and return to step 4. The new model
, and return to step 4. The new model 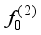 is trained by minimizing the cross-entropy loss of labeled sample
is trained by minimizing the cross-entropy loss of labeled sample 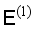 :
: 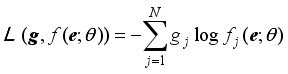 (2)
(2) 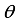 is the parameters in the model.
is the parameters in the model. 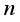 with
with 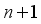 and return to step 1.
and return to step 1. 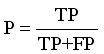 (3)
(3) 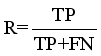 (4)
(4) 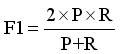 (5)
(5) 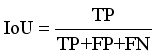 (6)
(6) Training set (single batch) | Validation set (single batch) | Test set |
|---|---|---|
54 (3,456) | 6 (384) | 32 (2,048) |
 , all data were rotated fiveepochs. The DenseNet was trained with the dataset and used to detect every batch of images and relabel them according to the detection results. The noise samples were added randomly in the training set, and the self-learning was performed for 34 iterations.
, all data were rotated fiveepochs. The DenseNet was trained with the dataset and used to detect every batch of images and relabel them according to the detection results. The noise samples were added randomly in the training set, and the self-learning was performed for 34 iterations. Label | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
background 1 | 3.85% | 0.52% | 0.67% | 0.00% | 0.00% | 0.00% |
background 2 | 10.75% | 2.92% | 1.56% | 1.78% | 0.70% | 0.00% |
background 3 | — | 6.12% | 6.90% | 0.00% | 0.00% | 0.00% |
background 4 | — | 7.39% | 3.63% | 0.00% | 0.00% | 0.00% |
background 5 | — | — | 0.00% | 0.00% | 0.00% | 0.00% |
background 6 | — | — | 1.05% | 0.00% | 0.00% | 0.00% |
background 7 | — | — | — | 12.73% | 0.00% | 0.00% |
background 8 | — | — | — | 0.00% | 0.00% | 0.00% |
background 9 | — | — | — | — | 0.00% | 0.00% |
background 10 | — | — | — | — | 0.00% | 0.00% |
background 11 | — | — | — | — | 0.00% | 0.00% |
background 12 | — | — | — | — | — | 0.32% |
crack 1 | 16.67% | 6.45% | 0.00% | 14.29% | 0.00% | 0.00% |
crack 2 | 42.20% | 24.32% | 19.35% | 14.71% | 23.40% | 15.56% |
crack 3 | — | 82.42% | 57.45% | 52.78% | 54.81% | 7.32% |
crack 4 | — | 46.09% | 11.94% | 30.26% | 48.84% | 4.76% |
crack 5 | — | — | 61.76% | 42.31% | 48.15% | 30.00% |
crack 6 | — | — | 54.93% | 40.43% | 24.14% | 17.24% |
crack 7 | — | — | — | 34.78% | 0.00% | 0.00% |
crack 8 | — | — | — | 17.65% | 31.25% | 0.00% |
crack 9 | — | — | — | — | 0.00% | 0.00% |
Model | depth | Number of layers | parameter | Precision (%) | Recall (%) | F1 (%) | IoU (%) |
|---|---|---|---|---|---|---|---|
AlexNet | 8 | 25 | 61 M | 85.15% | 86.28% | 85.71% | 75.00% |
GoogleNet | 22 | 144 | 7 M | 90.87% | 83.63% | 87.10% | 77.14% |
VGG16 | 16 | 41 | 138 M | 96.77% | 94.17% | 95.45% | 91.30% |
VGG19 | 19 | 47 | 144 M | 91.63% | 95.44% | 93.50% | 87.79% |
ResNet18 | 18 | 71 | 11.7 M | 84.39% | 76.89% | 80.47% | 67.32% |
ResNet50 | 50 | 177 | 25.6 M | 83.09% | 74.14% | 78.36% | 64.42% |
ResNet101 | 101 | 347 | 44.6 M | 92.75% | 84.21% | 88.28% | 79.01% |
DenseNet | 201 | 708 | 20 M | 83.80% | 69.44% | 75.95% | 61.22% |
IoU | Intersection over Union |
CNN | Convolutional Neural Network |
ML | Machine Learning |
SVM | Support Vector Machine |
FCN | Fully Convolutional Network |
P | Precision |
R | Recall |
TP | True Positive |
TN | True Negative |
FP | False Positive |
FN | False Negative |
| [1] | Zhang, J.; Yang, X.; Wang, W.; Brilakis, I.; Davletshina, D.; Wang, H.; Cao, M. Segment-to-track for pavement crack with light-weight neural network on unmanned wheeled robot. Automation in Construction 2024, 161, 105346, |
| [2] | Yu, Z.; Shen, Y.; Zhang, Y.; Xiang, Y. Automatic crack detection and 3D reconstruction of structural appearance using underwater wall-climbing robot. Automation in Construction 2024, 160, 105322, |
| [3] | Kirschke, K. R.; Velinsky, S. A. Histogram-Based Approach for Automated Pavement-Crack Sensing. Journal of Transportation Engineering 1992, 118, 700-710, |
| [4] | Bhutani, K. R.; Battou, A. An application of fuzzy relations to image enhancement. Pattern Recognition Letters 1995, 16, 901-909, |
| [5] | Oliveira, H.; Correia, P. L. Automatic road crack segmentation using entropy and image dynamic thresholding. In Proceedings of 2009 17th European Signal Processing Conference. |
| [6] | Ying, L.; Salari, E. Beamlet Transform-Based Technique for Pavement Crack Detection and Classification. Computer-Aided Civil and Infrastructure Engineering 2010, 25, 572-580, |
| [7] | Ikhlas, A.; Osama, A.; E., K. M. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. Journal of Computing in Civil Engineering 2003, 17, 255-263, |
| [8] | Li, Q.; Zou, Q.; Zhang, D.; Mao, Q. FoSA: F* Seed-growing Approach for crack-line detection from pavement images. Image and Vision Computing 2011, |
| [9] | Cheng, H. D.; Shi, X. J.; Glazier, C. Real-Time Image Thresholding Based on Sample Space Reduction and Interpolation Approach. Journal of Computing in Civil Engineering 2003, 17, 264-272, |
| [10] | Huang, Y.; Xu, B. Automatic inspection of pavement cracking distress. Journal of Electronic imaging 2006, 15, 013017, |
| [11] | al, M. G. e. Adaptive Road Crack Detection System by Pavement Classification. Sensors 2011, 11, 9628-9657, |
| [12] | Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognition Letters 2011, 33, 227-238, |
| [13] | Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Transactions on Intelligent Transportation Systems 2016, 17, 3434-3445, |
| [14] | Teng, S.; Liu, A.; Wu, Z.; Chen, B.; Ye, X.; Fu, J.; Kitiporncha, S.; Yang, J. Automated detection of underwater cracks based on fusion of optical and texture information. Engineering Structures 2024, 315, 118515, |
| [15] | Bai, S.; Ma, M.; Yang, L.; Liu, Y. Pixel-wise crack defect segmentation with dual-encoder fusion network. Construction and Building Materials 2024, 426, 136179, |
| [16] | Zhang, L.; Yang, F.; Zhang, Y. D.; Zhu, Y. J. Road crack detection using deep convolutional neural network. In Proceedings of 2016 IEEE International Conference on Image Processing (ICIP), 25-28 Sept. 2016; pp. 3708-3712. |
| [17] |
Wang, K. C. P.; Zhang, A.; Li, J. Q.; Fei, Y.; Chen, C.; Li, B. Deep Learning for Asphalt Pavement Cracking Recognition Using Convolutional Neural Network; 2017;
https://doi.org/10.1061/9780784480922.015 pp. 166-177 |
| [18] | Alfarrarjeh, A.; Trivedi, D.; Kim, S. H.; Shahabi, C. A Deep Learning Approach for Road Damage Detection from Smartphone Images. In Proceedings of 2018 IEEE International Conference on Big Data (Big Data), 10-13 Dec. 2018; pp. 5201-5204. |
| [19] | Hoang, N.; Nguyen, Q.; Tran, V. Automatic recognition of asphalt pavement cracks using metaheuristic optimized edge detection algorithms and convolution neural network. Automation in Construction 2018, 94, 203-213, |
| [20] | Tong, Z.; Gao, J.; Han, Z.; Wang, Z. Recognition of asphalt pavement crack length using deep convolutional neural networks. Road Materials and Pavement Design 2018, 19, 1334-1349, |
| [21] | Zhang, A.; Wang, K. C. P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J. Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Computer-Aided Civil and Infrastructure Engineering 2017, 32, 805-819, |
| [22] | Cha, Y.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Computer-Aided Civil and Infrastructure Engineering 2017, 32, 361-378, |
| [23] | Gopalakrishnan, K.; Khaitan, S. K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with transfer learning for computer vision-based data-driven pavement distress detection. Construction and Building Materials 2017, 157, 322-330, |
| [24] | Chen, F.; Jahanshahi, M. R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Transactions on Industrial Electronics 2018, 65, 4392-4400, |
| [25] | Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; H. Omata. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Computer-Aided Civil and Infrastructure Engineering 2018, 33, 1127-1141, |
| [26] | Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road Damage Detection and Classification with Faster R-CNN. In Proceedings of 2018 IEEE International Conference on Big Data (Big Data), 10-13 Dec. 2018; pp. 5220-5223. |
| [27] | Arya, D.; Maeda, H.; Ghosh, S. K.; Toshniwal, D.; Mraz, A.; Kashiyama, T.; Sekimoto, Y. Transfer Learning-based Road Damage Detection for Multiple Countries. 2020; p arXiv: 2008.13101. |
| [28] | Cha, Y.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Computer-Aided Civil and Infrastructure Engineering 2018, 33, 731-747, |
| [29] | Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Computer-Aided Civil and Infrastructure Engineering 2018, 33, 1090-1109, |
| [30] | Liu, J.; Yang, X.; Lau, S.; Wang, X.; Luo, S.; Lee, V. C.; Ding, L. Automated pavement crack detection and segmentation based on two-step convolutional neural network. Computer-Aided Civil and Infrastructure Engineering 2020, 35, 1291-1305, |
| [31] | Blum, A.; Mitchell, T. Combining labeled and unlabeled data with co-training. In Proceedings of Proceedings of the eleventh annual conference on Computational learning theory, Madison, Wisconsin, USA; pp. 92–100. |
| [32] | Nigam, K.; McCallum, A. K.; Thrun, S.; Mitchell, T. Text Classification from Labeled and Unlabeled Documents using EM. Machine Learning 2000, 39, 103-134, |
| [33] | Lee, D. Pseudo-Label: The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks. ICML 2013 Workshop: Challenges in Representation Learning (WREPL) 2013. |
| [34] | Xie, Q.; Luong, M. T.; Hovy, E.; Le, Q. V. Self-Training With Noisy Student Improves ImageNet Classification. In Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 13-19 June 2020; pp. 10684-10695. |
| [35] | Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of NIPS. |
| [36] | Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. 2014; |
| [37] | Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. 2014. |
| [38] | He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. |
APA Style
Yang, J., Sun, X., Teng, S. (2024). Automatic Road Crack Detection Using Convolutional Neural Network Based on Semi-Supervised Learning. Engineering and Applied Sciences, 9(4), 69-82. https://doi.org/10.11648/j.eas.20240904.13
ACS Style
Yang, J.; Sun, X.; Teng, S. Automatic Road Crack Detection Using Convolutional Neural Network Based on Semi-Supervised Learning. Eng. Appl. Sci. 2024, 9(4), 69-82. doi: 10.11648/j.eas.20240904.13
AMA Style
Yang J, Sun X, Teng S. Automatic Road Crack Detection Using Convolutional Neural Network Based on Semi-Supervised Learning. Eng Appl Sci. 2024;9(4):69-82. doi: 10.11648/j.eas.20240904.13
@article{10.11648/j.eas.20240904.13,
author = {Jun Yang and Xiaoli Sun and Shuai Teng},
title = {Automatic Road Crack Detection Using Convolutional Neural Network Based on Semi-Supervised Learning
},
journal = {Engineering and Applied Sciences},
volume = {9},
number = {4},
pages = {69-82},
doi = {10.11648/j.eas.20240904.13},
url = {https://doi.org/10.11648/j.eas.20240904.13},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.eas.20240904.13},
abstract = {Crack detection in pavements is a critical task for infrastructure maintenance, but it often requires extensive manual labeling of training samples, which is both time-consuming and labor-intensive. To address this challenge, this paper proposes a semi-supervised learning approach based on a DenseNet classification model to detect pavement cracks more efficiently. The primary objective is to leverage a small set of labeled samples to improve the model's performance by incorporating a large number of unlabeled samples through semi-supervised learning. This method enhances the DenseNet model's ability to generalize by iteratively learning from new unlabeled datasets. As a result, the proposed approach not only reduces the need for extensive manual labeling but also mitigates issues related to label inconsistency and errors in the original labels. The experimental results demonstrate that the semi-supervised DenseNet model achieves a prediction precision of 96.77% and a recall of 94.17%, with an F1 score of 95.45% and an Intersectidn over Union (IoU) of 91.30%. These metrics highlight the model's high accuracy and effectiveness in crack detection. The proposed method not only improves label quality and model performance but also offers practical value for engineering applications in the field of pavement maintenance, making it a valuable tool for infrastructure management.
},
year = {2024}
}
TY - JOUR T1 - Automatic Road Crack Detection Using Convolutional Neural Network Based on Semi-Supervised Learning AU - Jun Yang AU - Xiaoli Sun AU - Shuai Teng Y1 - 2024/08/30 PY - 2024 N1 - https://doi.org/10.11648/j.eas.20240904.13 DO - 10.11648/j.eas.20240904.13 T2 - Engineering and Applied Sciences JF - Engineering and Applied Sciences JO - Engineering and Applied Sciences SP - 69 EP - 82 PB - Science Publishing Group SN - 2575-1468 UR - https://doi.org/10.11648/j.eas.20240904.13 AB - Crack detection in pavements is a critical task for infrastructure maintenance, but it often requires extensive manual labeling of training samples, which is both time-consuming and labor-intensive. To address this challenge, this paper proposes a semi-supervised learning approach based on a DenseNet classification model to detect pavement cracks more efficiently. The primary objective is to leverage a small set of labeled samples to improve the model's performance by incorporating a large number of unlabeled samples through semi-supervised learning. This method enhances the DenseNet model's ability to generalize by iteratively learning from new unlabeled datasets. As a result, the proposed approach not only reduces the need for extensive manual labeling but also mitigates issues related to label inconsistency and errors in the original labels. The experimental results demonstrate that the semi-supervised DenseNet model achieves a prediction precision of 96.77% and a recall of 94.17%, with an F1 score of 95.45% and an Intersectidn over Union (IoU) of 91.30%. These metrics highlight the model's high accuracy and effectiveness in crack detection. The proposed method not only improves label quality and model performance but also offers practical value for engineering applications in the field of pavement maintenance, making it a valuable tool for infrastructure management. VL - 9 IS - 4 ER -
Technology Research and Development Department, Guangzhou Municipal Engineering Testing Co., Ltd., Guangzhou, The People's Republic of China
Technology Research and Development Department, Guangzhou Municipal Engineering Testing Co., Ltd., Guangzhou, The People's Republic of China
Technology Research and Development Department, Guangzhou Municipal Engineering Testing Co., Ltd., Guangzhou, The People's Republic of China
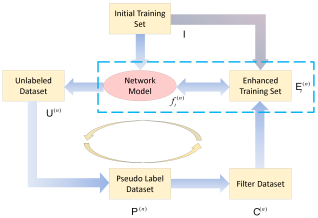
Figure 1. Semi-supervised learning framework diagram; outside the dotted box is pseudo labelling, inside the dotted box is self-learning.
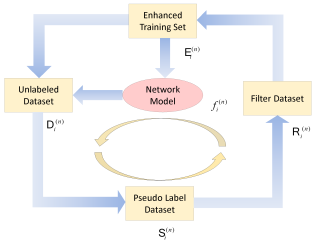
Figure 2. Schematic diagram of self-learning framework.
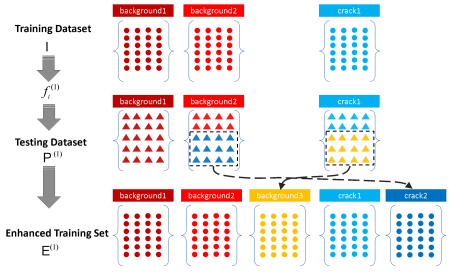
Figure 3. The training set is expanded by pseudo labelling. Each color dot represents a training set sample and its label, and each color triangle represents a pseudo labeled sample and its label.
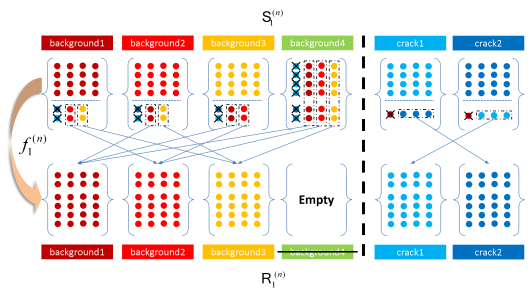
Figure 4. The training set is contracted by self-learning, and various color dots represent the samples and their labels.
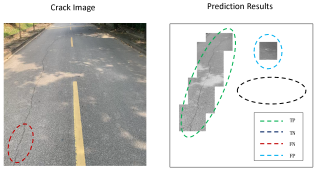
Figure 5. Example of classification of model test results.

Figure 6. Examples of initial training set.
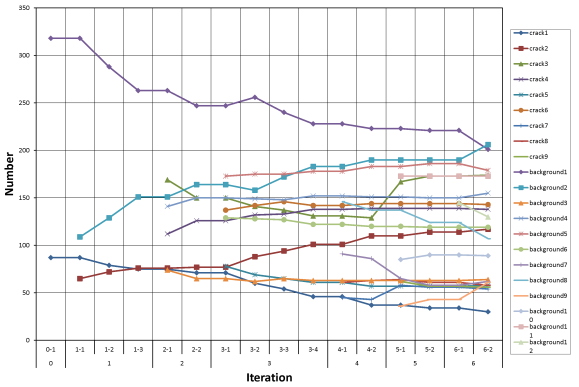
Figure 7. The change of the sample number of each label in the training set during the semi-supervised learning process of the model.
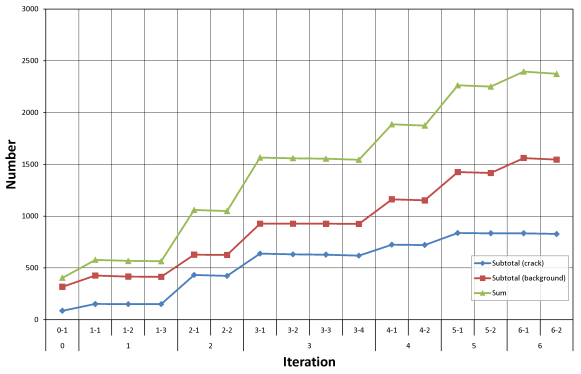
Figure 8. The change of the total number of samples of two types of labels in the training set during the iterative learning process of the model.

Figure 9. Example of crack sequence detected by the DenseNet.

Figure 10. Background sequences detected by the DenseNet.
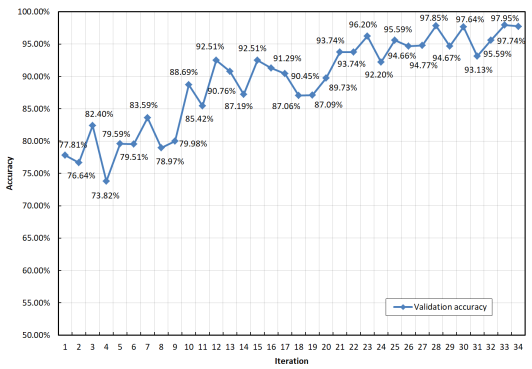
Figure 11. Validation accuracy of the training process.
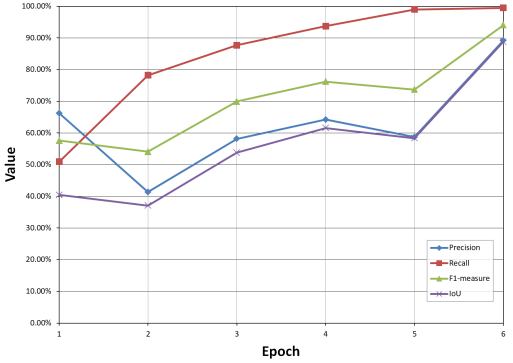
Figure 12. Changes of evaluation indexes of test set with the iteration of the training model.

Figure 13. Testing results of different test round.
Information




 denotes the number of pseudo labelling iterations,
denotes the number of pseudo labelling iterations,  represents the iteration number s of self-learning in each round of pseudo labelling
represents the iteration number s of self-learning in each round of pseudo labelling





