This work introduces a novel Convolutional Block Attention Module (CBAM) along with Convolutional Neural Network (CNN) architecture for the recognition of imagined speech electroencephalography (EEG) data. The real-time data is recorded in Biomedical Signal Processing Laboratory, IIT Roorkee. The Pearson correlation (P) method is utilized to gain understanding of neural activity during speech imagination. The proposed CBAM model leverages both spatial and channel attention, allowing the model to selectively focus on the most distinguishing regions. The incorporation of the CBAM mechanism enhances feature representation by adaptively emphasizing the most informative spatial and channel-wise EEG components, thereby improving both model performance and interpretability. This model also utilizes binary and multiclass classification of imagined speech from correlation-based EEG feature images. The subject independent and subject-dependent classification accuracies obtained from P feature images range from 52.72±7.1% to 68.20±5.3% and 67.47±5.8% to 88.09±4.2% respectively. The results suggest that correlation-based feature representation effectively captures the underlying neural dynamics associated with imagined speech. Comparative analysis with existing state-of-the-art methods indicates that the proposed model achieves improved classification accuracy and generalization, validating its effectiveness for EEG-based imagined speech decoding. These findings indicate the potential of the proposed approach for reliable and scalable brain–computer interface (BCI) applications in real-world scenarios.
| Published in | International Journal of Medical Case Reports (Volume 5, Issue 1) |
| DOI | 10.11648/j.ijmcr.20260501.12 |
| Page(s) | 6-14 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2026. Published by Science Publishing Group |
EEG, Deep Learning, Signal Processing, Imagined Speech, Attention
Layer | Layer Type | No. of Filters | Kernel Size | Stride | Activation |
|---|---|---|---|---|---|
Conv_1 | Conv2D | 32 | 3x3 | 1 | ReLU |
Conv_2 | Conv2D | 64 | 3x3 | 1 | ReLU |
Conv_3 | Conv2D | 128 | 5x5 | 1 | ReLU |
Layer | Layer Type | Pool Size | Stride |
|---|---|---|---|
MaxPooling_1 | MaxPooling2D | 2x2 | 2 |
MaxPooling_2 | MaxPooling2D | 2x2 | 2 |
Layer | Layer Type | Drop Rate |
|---|---|---|
Dropout_1 | Dropout | 0.25 |
Layer | Layer Type | Neurons | Activation |
|---|---|---|---|
Dense_1 | Dense | 128 | Tanh |
Task | Layer Type | Neurons | Activation |
|---|---|---|---|
Binary | Dense | 2 | Sigmoid |
4-Class | Dense | 4 | Softmax |
8-Class | Dense | 8 | Softmax |
Module | Type | Kernel Size |
|---|---|---|
CBAM | Attention | 5x5 |
Parameter | Value |
|---|---|
Optimizer | Adam |
Learning Rate | 0.0005 |
Batch Size | 16 |
Epochs | 40 |
Loss (Binary) | Binary Cross-Entropy |
Loss (Multi-class) | Categorical Cross-Entropy |
Validation | 10-fold CV |
Subject | 4 Class | 8 Class |
|---|---|---|
S1 | 70.12±1.36 | 50.42±1.54 |
S2 | 71.83±3.2 | 52.53±3.12 |
S3 | 74.15±1.9 | 51.64±2.54 |
S4 | 72.17±3.1 | 50.31±1.54 |
S5 | 70.69±4.1 | 52.31±4.5 |
S6 | 75.48±2.7 | 53.38±2.67 |
S7 | 73.37±1.78 | 49.62±3.41 |
S8 | 71.12±1.39 | 51.17±5.12 |
S9 | 72.67±2.4 | 52.63±2.43 |
S10 | 75.32±1.67 | 49.93±1.58 |
Model Variant | Accuracy (%) |
|---|---|
CNN (Baseline) | 62.3 |
CNN + Pearson Correlation | 69.2 |
CNN + CBAM | 73.4 |
Proposed | 76.7 |
CBAM | Convolutional Block Attention Module |
CNN | Convolutional Neural Network |
EEG | Electroencephalography |
P | Pearson Correlation |
BCI | Brain Computer Interface |
DL | Deep Learning |
ML | Machine Learning |
| [1] | J. Fumanal-Idocin et al., “Supervised penalty-based aggregation applied to motor-imagery based brain-computer-interface,” Pattern Recognit., vol. 145, p. 109924, Jan. 2024, |
| [2] | A. Mobaien, R. Boostani, and S. Sanei, “Improving the performance of P300-based BCIs by mitigating the effects of stimuli-related evoked potentials through regularized spatial filtering,” J. Neural Eng., vol. 21, no. 1, p. 016023, Feb. 2024, |
| [3] | A. Singh and A. Gumaste, “Decoding Imagined Speech and Computer Control using Brain Waves,” J. Neurosci. Methods, vol. 358, p. 109196, Jul. 2021, |
| [4] | M. Bisla and R. Shyam Anand, “Transfer Learning Enabled Imagined Speech Interpretation Using Phase-Based Brain Functional Connectivity and Power Analysis,” IEEE Access, vol. 12, pp. 108399–108413, 2024, |
| [5] | A. A. Torres-García, C. A. Reyes-García, L. Villaseñor-Pineda, and G. García-Aguilar, “Implementing a fuzzy inference system in a multi-objective EEG channel selection model for imagined speech classification,” Expert Syst. Appl., vol. 59, pp. 1–12, Oct. 2016, |
| [6] | C. S. DaSalla, H. Kambara, M. Sato, and Y. Koike, “Single-trial classification of vowel speech imagery using common spatial patterns,” Neural Networks, vol. 22, no. 9, pp. 1334–1339, Nov. 2009, |
| [7] | B. M. Idrees and O. Farooq, “Vowel classification using wavelet decomposition during speech imagery,” in 2016 3rd International Conference on Signal Processing and Integrated Networks (SPIN), IEEE, Feb. 2016, pp. 636–640. |
| [8] | B. Min, J. Kim, H. Park, and B. Lee, “Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram,” Biomed Res. Int., vol. 2016, pp. 1–11, 2016, |
| [9] | C. Cooney, R. Folli, and D. Coyle, “Optimizing Layers Improves CNN Generalization and Transfer Learning for Imagined Speech Decoding from EEG,” in 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), IEEE, Oct. 2019, pp. 1311–1316. |
| [10] | K. Brigham and B. V. K. V. Kumar, “Imagined Speech Classification with EEG Signals for Silent Communication: A Preliminary Investigation into Synthetic Telepathy,” in 2010 4th International Conference on Bioinformatics and Biomedical Engineering, IEEE, Jun. 2010, pp. 1–4. |
| [11] | M. N. I. Qureshi, B. Min, H.-J. Park, D. Cho, W. Choi, and B. Lee, “Multiclass Classification of Word Imagination Speech With Hybrid Connectivity Features,” IEEE Trans. Biomed. Eng., vol. 65, no. 10, pp. 2168–2177, Oct. 2018, |
| [12] | A. Kamble, P. Ghare, and V. Kumar, “Machine-learning-enabled adaptive signal decomposition for a brain-computer interface using EEG,” Biomed. Signal Process. Control, vol. 74, p. 103526, Apr. 2022, |
| [13] | A. Kamble, P. H. Ghare, and V. Kumar, “Optimized Rational Dilation Wavelet Transform for Automatic Imagined Speech Recognition,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–10, 2023, |
| [14] | A. Kamble, P. H. Ghare, V. Kumar, A. Kothari, and A. G. Keskar, “Spectral Analysis of EEG Signals for Automatic Imagined Speech Recognition,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–9, 2023, |
| [15] | A. Kamble, P. H. Ghare, and V. Kumar, “Deep-Learning-Based BCI for Automatic Imagined Speech Recognition Using SPWVD,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–10, 2023, |
| [16] | J. Benesty, J. Chen, Y. Huang, and I. Cohen, “Pearson Correlation Coefficient,” 2009, pp. 1–4. |
| [17] | A. Zamm, S. Debener, A. R. Bauer, M. G. Bleichner, A. P. Demos, and C. Palmer, “Amplitude envelope correlations measure synchronous cortical oscillations in performing musicians,” Ann. N. Y. Acad. Sci., vol. 1423, no. 1, pp. 251–263, Jul. 2018, |
| [18] | W. Hesse, E. Möller, M. Arnold, and B. Schack, “The use of time-variant EEG Granger causality for inspecting directed interdependencies of neural assemblies,” J. Neurosci. Methods, vol. 124, no. 1, pp. 27–44, Mar. 2003, |
| [19] | meenakshi bisla and R. S. Anand, “Machine learning based classification of imagined speech electroencephalogram data from the amplitude and phase spectrum of frequency domain EEG signal,” Biomed. Phys. Eng. Express, Sep. 2025, |
| [20] | R.S. Anand, Meenakshi Bisla, Anand Mohan, and Dilnawaz, “A Multi-Class Electroencephalography Dataset for Imagined Speech Decoding.,” Jan. 25, 2026, IEEE Dataport. |
| [21] | Z. Ji et al., “CBAM-DeepConvNet: Convolutional Block Attention Module-Deep Convolutional Neural Network for asymmetric visual evoked potentials recognition,” Brain-Apparatus Communication: A Journal of Bacomics, vol. 4, no. 1, Dec. 2025, |
| [22] | M. Bisla and R. S. Anand, “Speech imagery decoding from electroencephalography signals using an amalgamation of convolutional and recurrent neural networks,” Engineering Research Express, vol. 7, no. 2, p. 025232, Jun. 2025, |
| [23] | M. A. Morid, A. Borjali, and G. Del Fiol, “A scoping review of transfer learning research on medical image analysis using ImageNet,” Comput. Biol. Med., vol. 128, p. 104115, Jan. 2021, |
APA Style
Bisla, M., Anand, R. S. (2026). Imagined Speech Classification Using EEG and CBAM-CNN Model. International Journal of Medical Case Reports, 5(1), 6-14. https://doi.org/10.11648/j.ijmcr.20260501.12
ACS Style
Bisla, M.; Anand, R. S. Imagined Speech Classification Using EEG and CBAM-CNN Model. Int. J. Med. Case Rep. 2026, 5(1), 6-14. doi: 10.11648/j.ijmcr.20260501.12
@article{10.11648/j.ijmcr.20260501.12,
author = {Meenakshi Bisla and Radhey Shyam Anand},
title = {Imagined Speech Classification Using EEG and CBAM-CNN Model},
journal = {International Journal of Medical Case Reports},
volume = {5},
number = {1},
pages = {6-14},
doi = {10.11648/j.ijmcr.20260501.12},
url = {https://doi.org/10.11648/j.ijmcr.20260501.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ijmcr.20260501.12},
abstract = {This work introduces a novel Convolutional Block Attention Module (CBAM) along with Convolutional Neural Network (CNN) architecture for the recognition of imagined speech electroencephalography (EEG) data. The real-time data is recorded in Biomedical Signal Processing Laboratory, IIT Roorkee. The Pearson correlation (P) method is utilized to gain understanding of neural activity during speech imagination. The proposed CBAM model leverages both spatial and channel attention, allowing the model to selectively focus on the most distinguishing regions. The incorporation of the CBAM mechanism enhances feature representation by adaptively emphasizing the most informative spatial and channel-wise EEG components, thereby improving both model performance and interpretability. This model also utilizes binary and multiclass classification of imagined speech from correlation-based EEG feature images. The subject independent and subject-dependent classification accuracies obtained from P feature images range from 52.72±7.1% to 68.20±5.3% and 67.47±5.8% to 88.09±4.2% respectively. The results suggest that correlation-based feature representation effectively captures the underlying neural dynamics associated with imagined speech. Comparative analysis with existing state-of-the-art methods indicates that the proposed model achieves improved classification accuracy and generalization, validating its effectiveness for EEG-based imagined speech decoding. These findings indicate the potential of the proposed approach for reliable and scalable brain–computer interface (BCI) applications in real-world scenarios.},
year = {2026}
}
TY - JOUR T1 - Imagined Speech Classification Using EEG and CBAM-CNN Model AU - Meenakshi Bisla AU - Radhey Shyam Anand Y1 - 2026/04/15 PY - 2026 N1 - https://doi.org/10.11648/j.ijmcr.20260501.12 DO - 10.11648/j.ijmcr.20260501.12 T2 - International Journal of Medical Case Reports JF - International Journal of Medical Case Reports JO - International Journal of Medical Case Reports SP - 6 EP - 14 PB - Science Publishing Group SN - 2994-7049 UR - https://doi.org/10.11648/j.ijmcr.20260501.12 AB - This work introduces a novel Convolutional Block Attention Module (CBAM) along with Convolutional Neural Network (CNN) architecture for the recognition of imagined speech electroencephalography (EEG) data. The real-time data is recorded in Biomedical Signal Processing Laboratory, IIT Roorkee. The Pearson correlation (P) method is utilized to gain understanding of neural activity during speech imagination. The proposed CBAM model leverages both spatial and channel attention, allowing the model to selectively focus on the most distinguishing regions. The incorporation of the CBAM mechanism enhances feature representation by adaptively emphasizing the most informative spatial and channel-wise EEG components, thereby improving both model performance and interpretability. This model also utilizes binary and multiclass classification of imagined speech from correlation-based EEG feature images. The subject independent and subject-dependent classification accuracies obtained from P feature images range from 52.72±7.1% to 68.20±5.3% and 67.47±5.8% to 88.09±4.2% respectively. The results suggest that correlation-based feature representation effectively captures the underlying neural dynamics associated with imagined speech. Comparative analysis with existing state-of-the-art methods indicates that the proposed model achieves improved classification accuracy and generalization, validating its effectiveness for EEG-based imagined speech decoding. These findings indicate the potential of the proposed approach for reliable and scalable brain–computer interface (BCI) applications in real-world scenarios. VL - 5 IS - 1 ER -
School of Computer Science, UPES, Dehradun, India
Electrical Engineering Department, Indian Institute of Technology, Roorkee, India
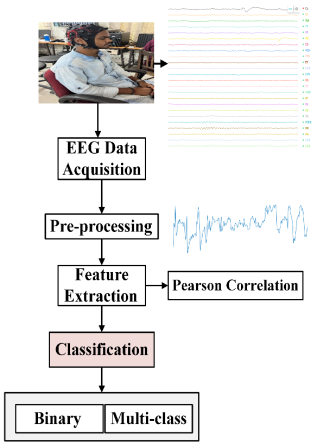
Figure 1. The comprehensive architecture of the proposed methodology.
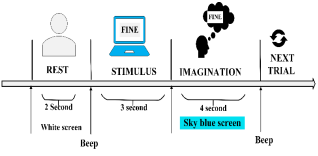
Figure 2. Experimental protocol of Dataset 1.
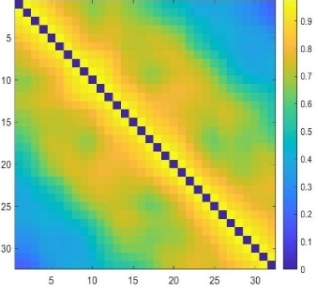
Figure 3. Pearson correlation EEG feature Image. The x-axis and y-axis correspond to 32 EEG channels.
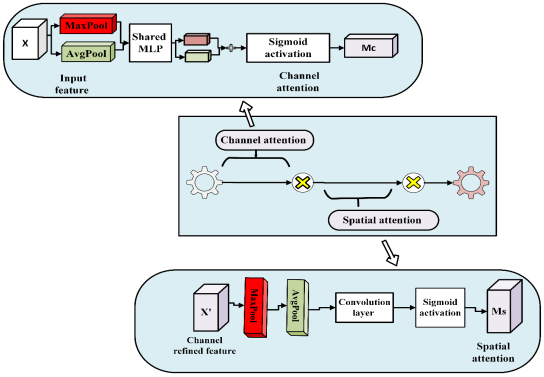
Figure 4. The functional architecture of CBAM attention module.
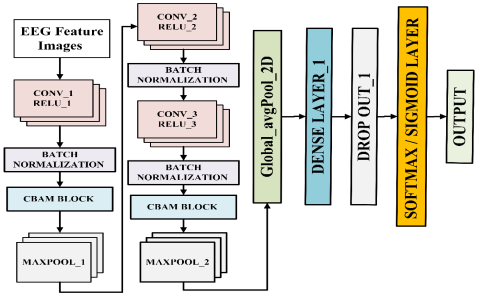
Figure 5. The architecture of proposed CBAM CNN model.
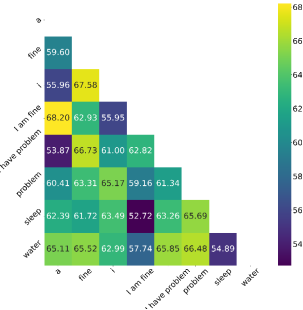
Figure 6. Heatmap of subject-independent binary classification of imagined words.

Figure 7. Comparison of performance of proposed model among different language categories in terms of the performance evaluation measures, such as Precision, Recall, F1-score, Kappa and Accuracy.
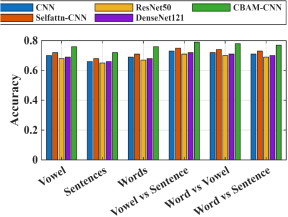
Figure 8. The comparative performance of different models for vowel, word, sentence, and cross-category classification tasks.
Information

