Abstract
Most Kenyan car owners prefer used vehicles due to their affordability, leading to a booming used car market. However, the absence of an objective pricing mechanism has led to inconsistent and subjective pricing, with prices varying significantly from seller to seller. This research aimed to provide a data-driven solution by incorporating key vehicle attributes. Using Design Science Research (DSR) methodology, the research implemented machine learning techniques: Random Forest (RF), Support Vector Machines (SVM), K-Nearest Neighbors (KNN), Gradient Boosting, Linear regression as base models, and Permutation for feature explanation to enhance accuracy and interpretability. The individual models were trained and evaluated using 5 cross-validation. Random Forest emerged as the best with a Mean Absolute Error of 0.1174, and Linear regression was the last with a Mean Absolute Error of 0.2635. For performance optimization, the four best baseline models (RF, SVM, KNN, and GB) were combined using a Stacking Regressor, which achieved an R-squared score of 0.9725, a mean absolute error (MAE) of 0.1137, and a mean squared error (MSE) of 0.2171, showing an improved predictive performance compared to individual models. Feature importance analysis identified mileage, car age, annual insurance, engine size, and usage type (Kenyan/Foreign) as the most influential features.
|
Published in
|
Science Frontiers (Volume 6, Issue 3)
|
|
DOI
|
10.11648/j.sf.20250603.15
|
|
Page(s)
|
96-105 |
|
Creative Commons
|

This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited.
|
|
Copyright
|
Copyright © The Author(s), 2025. Published by Science Publishing Group
|
Keywords
Used Car Market, Machine Learning, Price Prediction, Used Car Valuation
1. Introduction
The automotive industry is a key sector that contributes significantly to the growth of the economy. In Kenya, the industry has experienced significant growth. Playing a key role in the economy, it requires a reliable and consistent pricing mechanism that can be used for various purposes such as reselling, insurance, accounting, and leasing, among others. The existing pricing systems have consistently exhibited inconsistent and varying prices due to overreliance on subjective pricing. With the increased demand for used cars, there is a need for a standardized pricing tool that is data-driven
.
Significant progress has been made in the application of machine learning technology globally in the automotive industry. However, in Kenya, a unique challenge exists: the absence of a data-driven and standardized tool that can be used to predict the prices of used cars. Most existing studies focused on the use of single machine learning algorithms and partial variables and markets, particularly in Europe, India, the US, and Morocco, to mention but a few. These studies are not directly applicable to Kenya due to different market dynamics. This leads to mistrust, market inefficiencies, and losses since many people are relying on subjective pricing. To address these significant challenges, an ensemble machine learning model that incorporates vehicle attributes like make, mileage, year of manufacture, drive, engine size, annual insurance, usage type (Kenyan or Foreign), horsepower, torque, fuel type, and acceleration is important. Such a model would provide accurate price predictions, promoting market transparency and reducing inefficiencies. This boosts trust and informed decision-making among the stakeholders in the Kenyan automotive sector.
2. Literature Review
Several researchers have developed models in the used car pricing sector. Despite this significant progress, the majority of them have relied on a single modeling technique, the use of a narrow scope or partial variables. For instance, in
the authors built a model for both the Bosnia and Herzegovina market. They developed it using an ensemble approach by combining Artificial Neural Networks, Support Vector Machines, and Random Forest to improve prediction accuracy. The data was obtained from a website known as autopijaca.ba, and it was tested in a Java application. The output of the model was 87.38%. On top of that, the researchers recommended the use of diversified datasets and a scope that can help to achieve generalization. This research addressed their recommendation by using a dataset obtained from Kenya’s online motor bazaars.
In
| [13] | Bergmann, S., & Feuerriegel, S. (2024). Machine learning for predicting used car resale prices using granular vehicle equipment information. Expert Systems with Applications, 125640. https://doi.org/10.1016/j.eswa.2024.125640 |
[13]
Bergmann and Feuerriegel, 2024 the researchers developed a machine learning model for predicting the used car prices using granular vehicle equipment in Europe. The study utilized an end-to-end automated preprocessing procedure for 50,000 equipment options and used a dataset of 92,239 sales records. The model achieved a Mean Absolute Error of 3.40%. The model was designed to handle changing equipment descriptions. Although this research produced better results, it focused on a single machine learning approach which creates an opportunity for future work to explore and apply ensemble techniques. Besides that, it focused on a specific category of attributes. This creates a room for addition of other relevant features to improve accuracy. Our study has incorporated new ensemble machine learning techniques and features.
In
| [6] | Bukvi´c, P. J. F. T. A. B. L.: Price prediction and classification of used-vehicles using supervised machine learning. Sustainability. 14(24), 17034 (2022). |
[6]
the authors present an overview of data-driven models for predicting the price of used vehicles in the Croatian market. The authors focused on key factors like the production year and kilometers driven. They gathered data from the online marketplace "Njuškalo". The study used linear regression to predict car prices.. They concluded that the predicted model has the highest accuracy with linear regression, where the main features (price and model) are available. This study is limited to Croatian Market and paid attention to only key factors (Production year and Kilometers driven) with linear regression as the specific machine learning technique. This calls for a need to do research that brings many features together and combines various machine learning techniques to identify which one predicts the price better.
In
on the other hand, the authors made use of Artificial Neural Networks to predict the price of used cars in the United States market. The model was trained with a dataset of 140,000 cars and 30 different but popular brands, and it was tested by the use of 35,000 cars. This resulted in result achieved a mean absolute error of 11%. Although the study achieved a significant output, it made use of a single model. This research combined different models, thus coming up with a champion model that yielded better prediction.
In order to predict used car prices in India,
the researchers carried out a study that aimed at developing supervised learning models integrating both Random Forest and Artificial Neural Networks. Machine learning models, Random Forest and linear regression, were tested on datasets, while an Artificial neural network was implemented using the Keras Regressor Algorithm. Random Forest emerged as the best by achieving the lowest error with a mean absolute error of 1.097 and an R2 value of 0.772. The researchers, however, suggested advancement in the future by testing different machine learning techniques for the refinement of the level of accuracy. This study addresses their recommendation by implementing different techniques.
In Morocco, to assist both buyers and sellers in predicting accurate prices of used cars,
| [11] | Mustapha Hankar, A. B.-H. Marouane Birjali: Used Car Price Prediction using Machine Learning: A Case Study. 2022 11th International Symposium on Signal, Image, Video and Communications (ISIVC) (2022). https://doi.org/10.1109/isivc54825.2022.9800719 |
[11]
the researchers came up with a regression model to determine the resale values of used cars. They collected a dataset from Avito, a local online e-commerce platform, using the BeautifulSoup library. They considered model, fiscal power, fuel type, mileage, and year of production as key features. The dataset used comprised a total of 8000 car records. Out of the models tested, the Gradient boosting regressor outperformed all other models by achieving an R2 of about 0.80. For future work, they recommended the addition of more features and a larger dataset for improved accuracy of predicted used car prices. This research added new features, and the dataset used was larger than theirs.
In Mauritius,
| [9] | Peerun, C. N. P. S. S.: Predicting the price of second-hand cars using artificial neural networks. International Journal of Computer and Information System (IJCIS)., 59-66 (2015). |
[9]
the authors carried out research using artificial neural networks to assess whether they can be used to predict the price of second-hand cars accurately. They collected a record of 200 cars in total from different sources such as newspaper advertisements and car websites. They collected factors like car brand, engine capacity, manufacturing year, and mileage. They developed four machine learning algorithms, and out of which, the support vector machine performed the best than compared to linear regression and artificial neural networks. Although this produced a good result, there was a challenge with higher-priced cars, where some predictions were significantly off from actual prices. They made use of the Mean absolute error as a metric to measure performance. This brings about a need to diversify the scope and size of the dataset and to use other machine learning techniques to determine which produces more accurate results.
In
the authors investigated the relationship between car attributes like year of registration, kilometers driven, and fuel type. The study made use of K-Nearest Neighbors (KNN) and Classification and Regression Trees (CART) on a dataset containing 300,000 entries. Out of the two, CART performed better than KNN by achieving a lower root mean square error of 4961.64 than KNN, which had 5581. The researchers recommended the addition of more features for future studies, like horsepower and torque, to mention but a few. This research incorporated more features; horsepower, torque and annual insurance.
In
| [7] | Bharambe, Prof. P., Bagul, B., Dandekar, S., & Ingle, P. (2022). Used Car Price Prediction using Different Machine Learning Algorithms. International Journal for Research in Applied Science and Engineering Technology, 10(4), 773-778. https://doi.org/10.22214/ijraset.2022.41300 |
[7]
the researchers proposed three regression algorithms to predict the price of used cars. The study used three supervised machine learning techniques: linear regression, lasso regression, and ridge regression. Python libraries like Numpy, Pandas, and Scikit-learn were used to build the model and design the project’s graphical user interface (GUI). The accuracy of the models was compared, with linear regression achieving 83.65%, lasso regression 87.09%, and ridge regression 84.00%. Lasso regression was used to make the final price prediction since it achieved the highest accuracy. The researchers recommended the use of other machine learning techniques and the collection of a larger dataset. The final price prediction was made using Lasso regression, as it provided the highest accuracy. This research utilized other models, thus addressing their recommendations.
The K-Nearest Neighbors regression model was used by
| [8] | Daniel Aprillio Budiono, K. J. W., M. J. W. Kevin Sander Utomo: Used car price prediction model: A machine learning approach. International Journal of Computer and Information System (IJCIS).5(1), 59-66 (2024) https://doi.org/10.29040/ijcis.v5i1.147 |
[8]
to predict the prices of used cars. KNN works well with data that is in a multi-dimensional and it is highly resistant to data that is noisy. In total, 504 used car data points were collected using a web scraping method. The model finally achieved an R2 of 98.8% and an error rate of 8.8%. This result can significantly assist both buyers and sellers in determining the prices of used cars. The study utilized only one model to predict the prices. This calls for an advanced approach of combining different models in order to determine which one performs better and gives more accuracy. Therefore, this study combined different models, thus coming up with an optimized model.
Despite the notable progress on this area of study, significant gaps still remain especially on geographical scope, inclusion of more variables and modelling techniques. Based on above studies, there is absence of research specifically modeling used car prices in the Kenyan market. It is evident as well that annual insurance and usage type (local or foreign) as variables have been overlooked in most studies; this research has incorporated them as critical features. On top of that, this research has addressed the gap in limited ensemble strategies and using a different combination of ensemble models compared to the ones used by previous studies. Finally, most studies have overlooked feature importance analysis. This study incorporated a permutation method that ranked variables based on their contribution score to the targeted variable.
3. Problem Statement
The reliance on inconsistent and subjective pricing methods has made the pricing of used cars a challenge. Sellers often overestimate vehicle prices to maximize profits, leading to long delays in sales, while buyers struggle with unreliable pricing information, which breeds mistrust. The existing price prediction models have not been tested on the Kenyan market, and due to unique market variabilities, they may not be directly applicable. In addition to that, most of these studies don’t explain the contribution of individual factors to the target variable (price). There is currently no data-driven, standardized tool to address these challenges in Kenya’s used-car market. To solve this problem, there is a need for a tailored ensemble machine learning model that incorporates key vehicle attributes, for instance, make, year of manufacture, drive, annual insurance, engine size, mileage, fuel type, horsepower, torque, usage type (Kenyan/Foreign), and acceleration. Such a model will provide accurate price predictions, reduce inefficiencies, and improve market transparency.
4. Objectives
4.1. Main Objectives
To develop an ensemble machine learning model that predicts the prices of used cars in the Kenyan market.
4.2. Specific Objectives
1. To identify the most important factors that should be considered when predicting the prices of used cars in Kenya.
2. To develop an ensemble machine learning model that can be used to predict used car prices in Kenya.
3. To validate the developed ensemble model using the real-world dataset.
4. To evaluate the performance of the validated model using appropriate metrics.
5. Methodology
This research study was guided by Design Science Research Methodology (DSR). This methodology emphasizes coming up with a practical artifact that gives a solution to real-world problems. Pricing of used cars being a challenge facing the Kenyan market industry at the moment, this methodology suits it well. The entire research was guided by the principles of DSR, which are: Problem identification, objectives for a solution, artifact design and development, demonstration, evaluation, and communication of the results.
5.1. Data
Data collection: The data used in this study was collected from Kenyan online motor bazaars, namely Kai and Karo, Gigi, Motor Hub, and Maridady, after being given a research and data collection permit by the National Commission for Science, Technology and Innovation (NACOSTI). These sites were selected because they have structured data with minimal inconsistencies. The dataset consisted of 13,667 records. It was collected through a web scraping method using BeautifulSoup, a Python library. The data was stored in a laptop's local drive.
5.2. Data Preprocessing
The data that was collected underwent preprocessing steps to make it suitable for machine learning. Data cleaning was performed due to revealed data quality issues. The price column had a missing data rate of 4.26%, and the year of manufacture column had 2308 records, which were recorded as 0. The annual insurance column also had notable missing values. These anomalies were subjected to imputation. StandardScaler was used to normalize all numerical features in order to prevent a single feature from disproportionately influencing the learning process. Categorical Features like fuel type underwent transformation by the use of OneHotEncoder, whereby the presence of an observable was denoted with “1” and absence was denoted with “0”.
5.3. Feature Engineering
During exploratory data analysis, price, mileage, engine size and horsepower were found to be highly skewed. In order to make them more symmetrical, they went through log transformation. Price column in particular, had extreme outliers, which made the distribution of data highly right-skewed, with a value of 6.86; a new price_log feature was formed. This reduced the value to 0.64, thus yielding a more symmetrical result. However, since it was a target variable, it was reversed back to normal form for testing purposes using original_price = np.exp(m1)(predicted_log_price) method. Furthermore, we created the car_age column from the year of manufacture by subtracting current_year-year_of_manufacture. This feature could easily tell the age of the car by subtracting the year of manufacture from the current year.
5.4. Model Development
Five baseline models were trained in this study. K-Nearest Neighbors, Random Forest, Support Vector Machines, Gradient Boosting, and Linear regression. The data used in this study was split into 80% for training and 20% for testing. The splitting of data was done randomly using a random_state=42 to ensure reproducibility. K-cross cross-validation was used for hyperparameter tuning and robust model evaluation with 5 folds. This ensured that the performance of the models was not depending on a single partition.
6. Results
The performance of the individual base models was evaluated using these performance metrics: R-squared (R
2), Mean Absolute Error (MAE), and Mean Squared Error (MSE), as shown in
Table 1 below.
Table 1. Performance of individual base models.
Model | R-Squared | MAE | MSE |
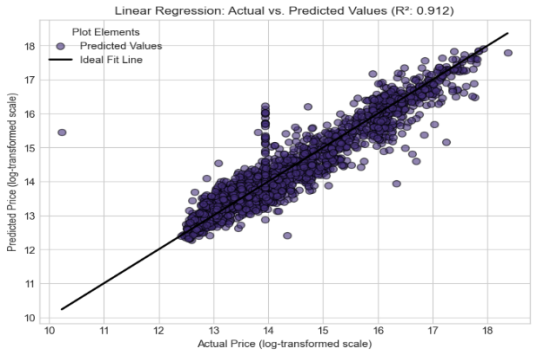
Linear-Regression | 0.9115 | 0.2635 | 0.3894 |
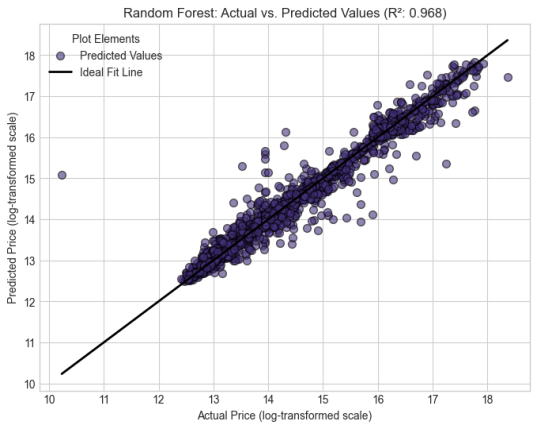
Random Forest | 0.9682 | 0.1174 | 0.2333 |
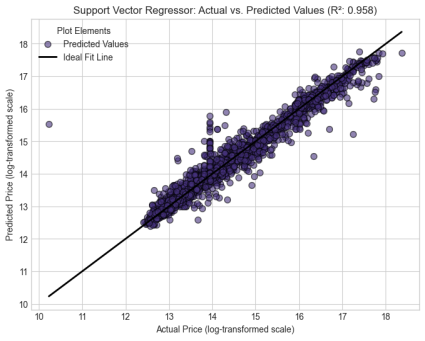
Support Vector Regression | 0.9584 | 0.1556 | 0.2670 |
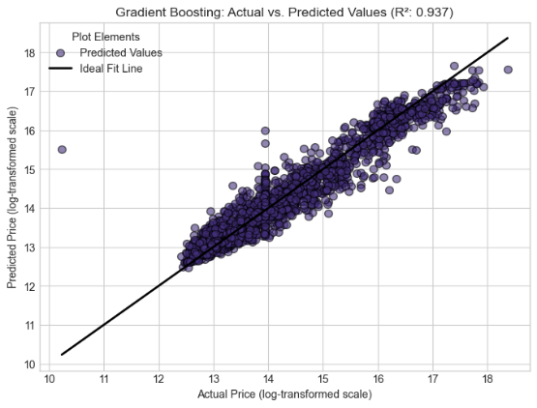
Gradient Boosting | 0.9365 | 0.2311 | 0.3298 |
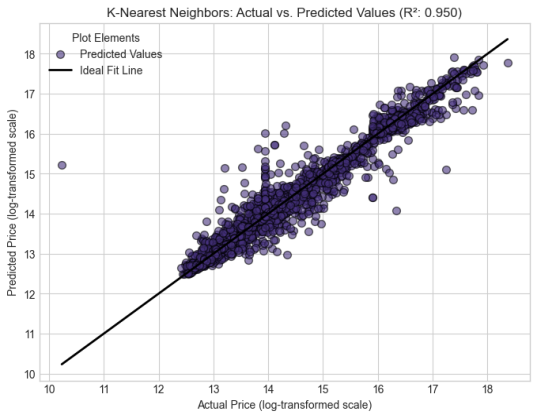
K-Nearest Neighbours | 0.9504 | 0.1634 | 0.2915 |
From the table above, it's evident that Random Forest emerged as the best with an MSE score of 0.233277, and linear regression was the last with an MSE score of 0.3894.
The following are the graphs for individual models
Figure 1,
Figure 2 and
Figure 3:
Figure 2. Linear Regression.
Figure 3. Gradient Boosting.
Figure 4. K-Nearest Neighbours.
Figure 5. Support Vector Machines.
6.1. Ensemble Model
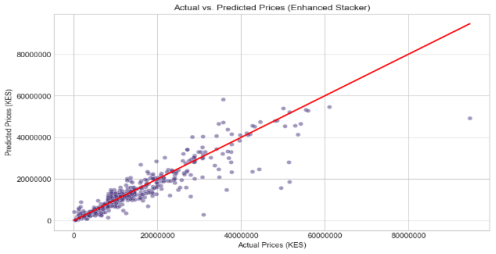
The best four performing models: Random Forest, Support Vector Machines, K-Nearest Neighbors, and Gradient Boosting, were combined in an ensemble strategy using a stacking regressor. The aim for this was to optimize the performance by coming up with a champion model that brings together the strengths of individual base models. Stacking combines the predictions of different base models into a meta-model that learns the optimal way of integrating base models. Linear Regression was chosen as the meta-model leading to superior performance with improved accuracy and generalization. The output of the champion model is as shown in
Table 2 below:
Table 2. Ensemble Model Performance Score Table.
Metric | Score |
R-squared (R2) | 0.9725 |
Mean Absolute Error (MAE) | 0.1137 |
Mean Squared Error (MSE) | 0.2171 |
Figure 6. Ensemble Model (Stacked Model) graph.
6.2. Feature Importance Analysis
One of the objectives of this study was to identify the individual contributions of features in predicting the target variable. To provide this interpretability, a permutation importance analysis was performed on the champion model. This is a model-agnostic technique that is used to quantify feature importance. It measures the decrease in the model’s performance when a single feature value is shuffled in a test. A feature that causes a large drop in performance when perturbed is considered more important. Below is
Table 3 showing the ranking of the more important features from the highest importance score to the least importance score.
Table 3. Feature Importance Scores.
Rank Feature | Score | Percentage |
Mileage | 0.147 | 37.43% |
Car_age | 0.0897 | 22.82% |
Annual_insurance | 0.0640 | 16.27% |
Usage_type (Kenyan or Foreign) | 0.0404 | 10.27% |
Engine_size | 0.0252 | 6.42% |
Body_type | 0.0094 | 2.40% |
Car_make | 0.0063 | 1.60% |
Based on the importance score as shown in
Table 3 above, the Mileage of the car and the Age of the car are fundamental in contributing towards the price of the car because they determine up to 60.25% of the total score of the price of used cars.
7. Discussion
The developed model has shown its strength in predicting the prices of the user cars in Kenya. It has resulted in important findings that are aligned with and expand existing literature. The individual models achieved a good predictive score, with Random Forest emerging as the best amongst the five. Their outputs were as follows: Random Forest performed the best with R2 score of 0.968249, benefiting from deep trees. It was followed by Support Vector Regressor with a score of 0.958412, followed by K-Nearest neighbors with a score of 0.950422, Gradient Boosting with a score of 0.936533 and finally Linear regression with an R2 value of 0.9115.
These scores were, however, combined into an ensemble using a Stacking approach. The developed model, as a result of the combination, outshone all of them by achieving a score of R-squared of 0.9725, a Mean Absolute Error (MAE) score of 0.1137, and a Root Mean Squared Error (RMSE) score of 0.2171. This indicates that it explains over 97% of the used car prices. This high accuracy furthermore has outshone some existing research, for instance, KNN (85% accuracy) by
| [12] | Samruddhi, K., & Ashok Kumar, R. (2020). Used Car Price Prediction using K-Nearest Neighbor Base Model. International Journal of Innovative Re-search in Applied Sciences and Engineering, 4(2), 629-632. https://doi.org/10.29027/ijirase.v4.i2.2020.629-632 |
[12]
. This is a reference to individual models. However, about ensemble models, this model performed better than some models like
who achieved 87.38% accuracy, and CatBoost, which achieved 86.05% accuracy in Bishkek. This model demonstrates a superior performance, which directly addresses the limited use of ensemble methods as identified in the literature re-view.
On the other hand, the feature importance analysis re-vealed key features that play a crucial role in the determination of the price of a used car in Kenya. The mileage, Car_age, Annual_insurance, usage_type (Kenyan or Foreign), engine_size, body_type, and car_make emerged as among the best seven features with the highest score, as demonstrated earlier. This one addresses the objective of identifying the key features that are used to predict the prices of used cars in Kenya. This also addresses the gap in feature engineering as mentioned by
, which emphasized the addition of more features like horsepower, torque, insurance, and many more. The performance metrics were well used, which explained the predictive nature of the ensemble model. In conclusion, the Stacked model performed better in the prediction by achieving an R-squared score value of 0.9725, which is 97% accurate than compared to individual models.
8. Conclusion
In conclusion, the study developed an ensemble model for predicting the prices of used cars. Data was obtained from Kenya's online Motor Bazaars, and it was preprocessed to ensure it is fit for the study. The study found out that mileage, car age (year of manufacture), annual insurance, usage type (Kenyan/Foreign), engine size, body type, and car make were the most important features. Four models were combined in an ensemble strategy using a Stacking regressor: Random Forest, Support Vector Machines, K-Nearest Neighbors, and Gradient Boosting, which was validated using real-world data obtained from Kenya online motor bazaars. The developed champion model demonstrated a great performance by achieving an R2 score of 0.9725, an MAE of 0.1137, and an RMSE of 0.2171. This one provides a practical artifact that can be used to predict the prices of used cars in Kenya.
9. Recommendation of Future Work
Industry policy makers and stakeholders should support the use of data-driven solutions in the automotive industry to enhance consistency and improve decision-making when pricing cars. Additionally, car dealers are encouraged to adopt data-driven tools for promoting fairness and competitive pricing. Finally, future researchers can expand the work by including real-time factors like currency exchange rates, the use of multi-modal models, incorporating natural language processing for interpreting user-submitted descriptions of car conditions, discovering more features, also with the current availability of cloud computing platforms, APIs and machine learning frameworks, it is possible to deploy the model as a web or mobile application. These technologies guarantee that predictions can be produced in real time with little latency by enabling the trained model to be hosted online and accessible by end users by user-friendly interfaces.
Abbreviations
K-Fold | A Cross-validation Method where K Represents the Number of Splits in the Dataset |
KNN | K-Nearest Neighbors |
MAE | Mean Absolute Error |
ML | Machine Learning |
R2 | R-squared (Coefficient of Determination) |
Acknowledgments
First, I take this opportunity to thank the management of the The Cooperative University for giving me an opportunity and conducive environment for learning. Special thanks to Dr. Shem Mbandu, Dean School of Computing and Mathematics, and Dr. Charles Katila, Chairperson Department of Computer Science and Information Technology who shared insights into the degree programme and its relevance that led to my enrolment in the University. Special thanks to my supervisors, Dr. Ronald Ojino and Dr. Fidelis Mukudi for advice, guidance, and encouragement that generated insights that shaped the research. To my father and mother, I say thank you for emotional support. You will always remain in my heart. To my sib-lings Esther and Macvivian who give hope in this World. Let this work inspire you.
Author Contributions
Moses Onserio: Conceptualization, Data curation, Formal Analysis, Methodology, Software and Writing - original draft.
Fidelis Mukudi: Supervision and general guidance throughout the research.
Funding
This work is not supported by any external funding.
Data Availability Statement
The data that support the findings of this study can be found at: https://www.kaiandkaro.com, https://www.gigi motors.co.ke, https://www.maridadymotors.com and https://www.motorhub.co.ke
Conflicts of Interest
The authors declare no conflicts of interest.
References
| [1] |
Foresights., M.: Kenya Used Car Market. Preprint at
https://mobilityforesights.com/product/kenya-used-car-market
(2024).
|
| [2] |
Munda, M. J. C.: Second hand cars price shocker as imports drop by Sh26bn. Business Daily. Preprint at
https://www.businessdailyafrica.com/bd/corporate/companies/second-hand-cars-price-shocker-as-imports-drop-by-sh26bn--4521986
(2024).
|
| [3] |
Gegic, I. B. K. D. M. Z. K. J. E.: Car price prediction using machine learning techniques. TEM Journal. 8(1), 113-118 (2019)
https://doi.org/10.18421/TEM81-16
|
| [4] |
Chandak, G. P. S. S. B. A. T. S. A.: Car price prediction using machine learning. International Journal of Computer Sciences and Engineering. 7(5), 444-450(2019)
https://doi.org/10.26438/ijcse/v7i5.444450
|
| [5] |
Moody, J., Farr, E., Papagelis, M., & Keith, D. R. (2021). The value of car ownership and use in the United States. Nature Sustainability, 4.
https://doi.org/10.1038/s41893-021-00731-5
|
| [6] |
Bukvi´c, P. J. F. T. A. B. L.: Price prediction and classification of used-vehicles using supervised machine learning. Sustainability. 14(24), 17034 (2022).
|
| [7] |
Bharambe, Prof. P., Bagul, B., Dandekar, S., & Ingle, P. (2022). Used Car Price Prediction using Different Machine Learning Algorithms. International Journal for Research in Applied Science and Engineering Technology, 10(4), 773-778.
https://doi.org/10.22214/ijraset.2022.41300
|
| [8] |
Daniel Aprillio Budiono, K. J. W., M. J. W. Kevin Sander Utomo: Used car price prediction model: A machine learning approach. International Journal of Computer and Information System (IJCIS).5(1), 59-66 (2024)
https://doi.org/10.29040/ijcis.v5i1.147
|
| [9] |
Peerun, C. N. P. S. S.: Predicting the price of second-hand cars using artificial neural networks. International Journal of Computer and Information System (IJCIS)., 59-66 (2015).
|
| [10] |
Varshitha, J. K., L. C. J.: Prediction Of Used Car Prices Using Artificial Neural Networks And Machine Learning. Preprint at
https://doi.org/10.1109/ICCCI54379.2022.9740817
(2022).
|
| [11] |
Mustapha Hankar, A. B.-H. Marouane Birjali: Used Car Price Prediction using Machine Learning: A Case Study. 2022 11th International Symposium on Signal, Image, Video and Communications (ISIVC) (2022).
https://doi.org/10.1109/isivc54825.2022.9800719
|
| [12] |
Samruddhi, K., & Ashok Kumar, R. (2020). Used Car Price Prediction using K-Nearest Neighbor Base Model. International Journal of Innovative Re-search in Applied Sciences and Engineering, 4(2), 629-632.
https://doi.org/10.29027/ijirase.v4.i2.2020.629-632
|
| [13] |
Bergmann, S., & Feuerriegel, S. (2024). Machine learning for predicting used car resale prices using granular vehicle equipment information. Expert Systems with Applications, 125640.
https://doi.org/10.1016/j.eswa.2024.125640
|
Cite This Article
-
APA Style
Onserio, M., Mukudi, F. (2025). Ensemble Machine Learning Model for Predicting Prices of Used Cars in Kenya. Science Frontiers, 6(3), 96-105. https://doi.org/10.11648/j.sf.20250603.15
 Copy
|
Copy
|
 Download
Download
ACS Style
Onserio, M.; Mukudi, F. Ensemble Machine Learning Model for Predicting Prices of Used Cars in Kenya. Sci. Front. 2025, 6(3), 96-105. doi: 10.11648/j.sf.20250603.15
Copy
|
Download
AMA Style
Onserio M, Mukudi F. Ensemble Machine Learning Model for Predicting Prices of Used Cars in Kenya. Sci Front. 2025;6(3):96-105. doi: 10.11648/j.sf.20250603.15
Copy
|
Download
-
@article{10.11648/j.sf.20250603.15,
author = {Moses Onserio and Fidelis Mukudi},
title = {Ensemble Machine Learning Model for Predicting Prices of Used Cars in Kenya
},
journal = {Science Frontiers},
volume = {6},
number = {3},
pages = {96-105},
doi = {10.11648/j.sf.20250603.15},
url = {https://doi.org/10.11648/j.sf.20250603.15},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.sf.20250603.15},
abstract = {Most Kenyan car owners prefer used vehicles due to their affordability, leading to a booming used car market. However, the absence of an objective pricing mechanism has led to inconsistent and subjective pricing, with prices varying significantly from seller to seller. This research aimed to provide a data-driven solution by incorporating key vehicle attributes. Using Design Science Research (DSR) methodology, the research implemented machine learning techniques: Random Forest (RF), Support Vector Machines (SVM), K-Nearest Neighbors (KNN), Gradient Boosting, Linear regression as base models, and Permutation for feature explanation to enhance accuracy and interpretability. The individual models were trained and evaluated using 5 cross-validation. Random Forest emerged as the best with a Mean Absolute Error of 0.1174, and Linear regression was the last with a Mean Absolute Error of 0.2635. For performance optimization, the four best baseline models (RF, SVM, KNN, and GB) were combined using a Stacking Regressor, which achieved an R-squared score of 0.9725, a mean absolute error (MAE) of 0.1137, and a mean squared error (MSE) of 0.2171, showing an improved predictive performance compared to individual models. Feature importance analysis identified mileage, car age, annual insurance, engine size, and usage type (Kenyan/Foreign) as the most influential features.
},
year = {2025}
}
Copy
|
Download
-
TY - JOUR
T1 - Ensemble Machine Learning Model for Predicting Prices of Used Cars in Kenya
AU - Moses Onserio
AU - Fidelis Mukudi
Y1 - 2025/08/28
PY - 2025
N1 - https://doi.org/10.11648/j.sf.20250603.15
DO - 10.11648/j.sf.20250603.15
T2 - Science Frontiers
JF - Science Frontiers
JO - Science Frontiers
SP - 96
EP - 105
PB - Science Publishing Group
SN - 2994-7030
UR - https://doi.org/10.11648/j.sf.20250603.15
AB - Most Kenyan car owners prefer used vehicles due to their affordability, leading to a booming used car market. However, the absence of an objective pricing mechanism has led to inconsistent and subjective pricing, with prices varying significantly from seller to seller. This research aimed to provide a data-driven solution by incorporating key vehicle attributes. Using Design Science Research (DSR) methodology, the research implemented machine learning techniques: Random Forest (RF), Support Vector Machines (SVM), K-Nearest Neighbors (KNN), Gradient Boosting, Linear regression as base models, and Permutation for feature explanation to enhance accuracy and interpretability. The individual models were trained and evaluated using 5 cross-validation. Random Forest emerged as the best with a Mean Absolute Error of 0.1174, and Linear regression was the last with a Mean Absolute Error of 0.2635. For performance optimization, the four best baseline models (RF, SVM, KNN, and GB) were combined using a Stacking Regressor, which achieved an R-squared score of 0.9725, a mean absolute error (MAE) of 0.1137, and a mean squared error (MSE) of 0.2171, showing an improved predictive performance compared to individual models. Feature importance analysis identified mileage, car age, annual insurance, engine size, and usage type (Kenyan/Foreign) as the most influential features.
VL - 6
IS - 3
ER -
Copy
|
Download