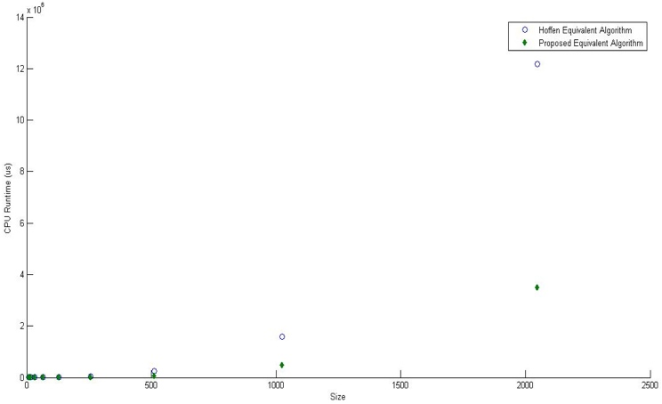
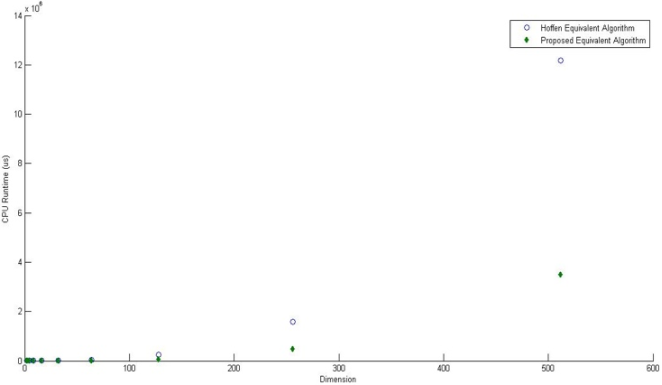
The Hoffman’s algorithm to test equivalency of linear codes is one of the techniques that have been used over the years; it is achieved by a comparison of codewords of the linear codes. However, this comparison technique becomes ineffective in instances where it is applied to linear codes with larger dimensions as it requires much run time complexity, space and size in comparing the codewords of each linear code. This paper proposes an optimised algorithm for testing the equivalency of linear codes, specifically addressing the limitations of the Hoffman method. To assess and compare the efficiencies of the Hoffman algorithm and the optimised algorithm, a set of nine carefully selected linear codes were subjected to equivalency testing. The CPU runtime of both algorithms was recorded using the C++ chrono library. The recorded runtime data was then utilized to create a scatter plot, offering a visual representation of the contrasting trends in CPU runtime between the two algorithms. The plot clearly indicate exponential growth in CPU runtime for the Hoffman algorithm as the length and dimension of the linear codes increases, in contrast, the proposed algorithm showcased a minimal growth in CPU runtime, indicating its superior efficiency and optimised performance.
| Published in | Mathematics and Computer Science (Volume 9, Issue 2) |
| DOI | 10.11648/j.mcs.20240902.11 |
| Page(s) | 26-35 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Linear Codes, Code Equivalency, Hoffman Algorithm, Codewords
A | B | A | B |
|---|---|---|---|
0 | 0 | 0 | 0 |
0 | 1 | 1 | 0 |
1 | 0 | 0 | 1 |
1 | 1 | 1 | 1 |
*Original code
A | B | C |
|---|---|---|
0 | 0 | 0 |
0 | 0 | 1 |
0 | 1 | 0 |
0 | 1 | 1 |
1 | 0 | 0 |
1 | 0 | 1 |
1 | 1 | 0 |
1 | 1 | 1 |
*Equivalent code with pattern 2,3,1
A | B | C |
|---|---|---|
0 | 0 | 0 |
0 | 1 | 0 |
1 | 0 | 0 |
1 | 1 | 0 |
0 | 0 | 1 |
0 | 1 | 1 |
1 | 0 | 1 |
1 | 1 | 1 |
*Original code
A | B | C | D |
|---|---|---|---|
0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 |
0 | 0 | 1 | 0 |
0 | 0 | 1 | 1 |
0 | 1 | 0 | 0 |
0 | 1 | 0 | 1 |
0 | 1 | 1 | 0 |
0 | 1 | 1 | 1 |
1 | 0 | 0 | 0 |
1 | 0 | 0 | 1 |
1 | 0 | 1 | 0 |
1 | 0 | 1 | 1 |
1 | 1 | 0 | 0 |
1 | 1 | 0 | 1 |
1 | 1 | 1 | 0 |
1 | 1 | 1 | 1 |
*Equivalent code with pattern 1,3,2,4
A | B | C | D |
|---|---|---|---|
0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 |
0 | 1 | 0 | 0 |
0 | 1 | 0 | 1 |
0 | 0 | 1 | 0 |
0 | 0 | 1 | 1 |
0 | 1 | 1 | 0 |
0 | 1 | 1 | 1 |
1 | 0 | 0 | 0 |
1 | 0 | 0 | 1 |
1 | 1 | 0 | 0 |
1 | 1 | 0 | 1 |
1 | 0 | 1 | 0 |
1 | 0 | 1 | 1 |
1 | 1 | 1 | 0 |
1 | 1 | 1 | 1 |
Original code
A | B | C | D |
|---|---|---|---|
0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 |
0 | 0 | 1 | 0 |
0 | 0 | 1 | 1 |
0 | 1 | 0 | 0 |
0 | 1 | 0 | 1 |
0 | 1 | 1 | 0 |
0 | 1 | 1 | 1 |
1 | 0 | 0 | 0 |
1 | 0 | 0 | 1 |
1 | 0 | 1 | 0 |
1 | 0 | 1 | 1 |
1 | 1 | 0 | 0 |
1 | 1 | 0 | 1 |
1 | 1 | 1 | 0 |
1 | 1 | 1 | 1 |
Equivalent code with pattern {1,3,2,4}
A | B | C | D | Position of 1’s in C | Position of 1’s in C ' | Diff. | SUM |
|---|---|---|---|---|---|---|---|
0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
0 | 0 | 0 | 1 | 4 | 4 | 0 | 0 |
0 | 1 | 0 | 0 | 3 | 2 | -1 | -1 |
0 | 1 | 0 | 1 | 3 4 | 2 4 | -1 0 | -2 |
0 | 0 | 1 | 0 | 2 | 3 | +1 | -1 |
0 | 0 | 1 | 1 | 2 4 | 3 4 | +1 0 | 0 |
0 | 1 | 1 | 0 | 2 3 | 2 3 | 0 0 | 0 |
0 | 1 | 1 | 1 | 2 3 4 | 2 3 4 | 0 0 0 | 0 |
1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
1 | 0 | 0 | 1 | 1 4 | 1 4 | 0 0 | 0 |
1 | 1 | 0 | 0 | 1 3 | 1 2 | 0 -1 | -1 |
1 | 1 | 0 | 1 | 1 3 4 | 1 2 4 | 0 -1 0 | -2 |
1 | 0 | 1 | 0 | 1 2 | 1 3 | 0 1 | -1 |
1 | 0 | 1 | 1 | 1 2 4 | 1 3 4 | 0 1 0 | 0 |
1 | 1 | 1 | 0 | 1 2 3 | 1 2 3 | 0 0 0 | 0 |
1 | 1 | 1 | 1 | 1 2 3 4 | 1 2 3 4 | 0 0 0 0 | 0 |
Length (n) | Dimension (k) | Hoffman Algorithm Runtime (μs) | Proposed Algorithm Runtime (μs) |
|---|---|---|---|
8 | 2 | 995 | 541 |
16 | 4 | 1031 | 548 |
32 | 8 | 1601 | 550 |
64 | 16 | 1998 | 557 |
128 | 32 | 15715 | 4006 |
256 | 64 | 48401 | 12764 |
512 | 128 | 239097 | 65436 |
1024 | 256 | 1580359 | 489754 |
2048 | 512 | 12166397 | 3510342 |
| [1] | W. K. Harrison, J. Almeida, M. R. Bloch, S. W. McLaughlin, and J. Barros, “Coding for secrecy: An overview of error-control coding techniques for physical-layer security,” IEEE Signal Processing Magazine. pp. 41–50, 2013. |
| [2] | N. Sendrier, “Finding the permutation between equivalent linear codes: the support splitting algorithm,” IEEE Trans Inf Theory, pp. 1193–1203, 2000, |
| [3] | N. T. Courtois, M. Finiasz, and N. Sendrier, “How to Achieve a McEliece-Based Digital Signature Scheme,” Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 2248, pp. 157–174, 2001, |
| [4] | M. Bardet, A. Otmani, and M. Saeed-Taha, “Permutation Code Equivalence is Not Harder Than Graph Isomorphism When Hulls Are Trivial,” IEEE International Symposium on Information Theory - Proceedings, vol. 2019-July, pp. 2464–2468, Jul. 2019, |
| [5] | D. G. Hoffman, Wal, D. A. Leonard, C. C. Lidner, K. T. Phelps, and C. A. Rodger, Coding Theory: The Essentials. USA: Marcel Dekker, Inc., 1991. |
| [6] | S. Gayathri Devi, K. Selvam, and S. P. Rajagopalan, “An abstract to calculate big o factors of time and space complexity of machine code,” in IET Conference Publications, 2011, pp. 844 – 847. |
| [7] | T. Dobravec, “Estimating the time complexity of the algorithms by counting the Java bytecode instructions,” in 2017 IEEE 14th International Scientific Conference on Informatics, INFORMATICS 2017 - Proceedings, 2018, pp. 74–79. |
| [8] | M. Zugelj, “Empirical Analysis Complexity of Algorithm,” University of Ljubljana, 2019. |
| [9] | M. Cherkaskyy and H. K. Murad, “Modern Problems of Radio Engineering, Telecommunications and Computer Science,” Institute of Electrical and Electronics Engineers (IEEE), Jul. 2006, pp. 45–45. |
| [10] | D. Zaparanuks and M. Hauswirth, “Algorithmic profiling,” in ACM SIGPLAN Notices, 2012, pp. 67–76. |
| [11] | S. F. Goldsmith, A. S. Aiken, and D. S. Wilkerson, “Measuring empirical computational complexity,” in 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, ESEC/FSE 2007, 2007, pp. 395–404. |
| [12] | J. Thiyagalingam, S. Walton, B. Duffy, A. Trefethen, and M. Chen, “Complexity plots,” Computer Graphics Forum, pp. 111–120, 2013, |
| [13] | T. R. Kelley, “Optimization, an Important Stage of Engineering Design,” 2010, Accessed: Oct. 22, 2021. [Online]. Available: |
| [14] |
L. Diego, “Essential Programming | Time Complexity,” Towards Data Science. [Online]. Available:
https://towardsdatascience.com/essential-programming-time-complexity-a95bb2608cac |
| [15] | B. Stroustrup, the C++ Programming Language 4Th Edition. 2013. |
| [16] |
“Measure execution time of a function in C++ - GeeksforGeeks.” Accessed: Oct. 22, 2021. [Online]. Available:
https://www.geeksforgeeks.org/measure-execution-time-function-cpp/ |
| [17] | Khan Academy, “Measuring an algorithm’s efficiency | AP CSP (article).” Accessed: Oct. 22, 2021. [Online]. Available: |
| [18] | R. M. Kubina, D. E. Kostewicz, K. M. Brennan, and S. A. King, “A Critical Review of Line Graphs in Behavior Analytic Journals,” Educational Psychology Review. pp. 583–598, 2017. |
| [19] | J. D. Lane and D. L. Gast, “Visual analysis in single case experimental design studies: Brief review and guidelines,” Neuropsychological Rehabilitation. pp. 445–463, 2014. |
| [20] | A. Ibrahim, P. Chun, and N. Kamoh, “A New [14 8 3]-Linear Code From the Aunu Generated [7 4 2] -Linear Code and the Known [7 4 3] Hamming Code Using the (U|U+V) Construction,” Journal of Applied & Computational Mathematics, vol. 07, no. 01, pp. 1–3, 2018, |
APA Style
Olaewe, O. O., Agbedemnab, P. A., Iddrisu, M. M. (2024). An Optimised Hoffman Algorithm for Testing Linear Code Equivalency. Mathematics and Computer Science, 9(2), 26-35. https://doi.org/10.11648/j.mcs.20240902.11
ACS Style
Olaewe, O. O.; Agbedemnab, P. A.; Iddrisu, M. M. An Optimised Hoffman Algorithm for Testing Linear Code Equivalency. Math. Comput. Sci. 2024, 9(2), 26-35. doi: 10.11648/j.mcs.20240902.11
AMA Style
Olaewe OO, Agbedemnab PA, Iddrisu MM. An Optimised Hoffman Algorithm for Testing Linear Code Equivalency. Math Comput Sci. 2024;9(2):26-35. doi: 10.11648/j.mcs.20240902.11
@article{10.11648/j.mcs.20240902.11,
author = {Olufemi Ololade Olaewe and Peter Awonnatemi Agbedemnab and Mohammed Muniru Iddrisu},
title = {An Optimised Hoffman Algorithm for Testing Linear Code Equivalency
},
journal = {Mathematics and Computer Science},
volume = {9},
number = {2},
pages = {26-35},
doi = {10.11648/j.mcs.20240902.11},
url = {https://doi.org/10.11648/j.mcs.20240902.11},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.mcs.20240902.11},
abstract = {The Hoffman’s algorithm to test equivalency of linear codes is one of the techniques that have been used over the years; it is achieved by a comparison of codewords of the linear codes. However, this comparison technique becomes ineffective in instances where it is applied to linear codes with larger dimensions as it requires much run time complexity, space and size in comparing the codewords of each linear code. This paper proposes an optimised algorithm for testing the equivalency of linear codes, specifically addressing the limitations of the Hoffman method. To assess and compare the efficiencies of the Hoffman algorithm and the optimised algorithm, a set of nine carefully selected linear codes were subjected to equivalency testing. The CPU runtime of both algorithms was recorded using the C++ chrono library. The recorded runtime data was then utilized to create a scatter plot, offering a visual representation of the contrasting trends in CPU runtime between the two algorithms. The plot clearly indicate exponential growth in CPU runtime for the Hoffman algorithm as the length and dimension of the linear codes increases, in contrast, the proposed algorithm showcased a minimal growth in CPU runtime, indicating its superior efficiency and optimised performance.
},
year = {2024}
}
TY - JOUR T1 - An Optimised Hoffman Algorithm for Testing Linear Code Equivalency AU - Olufemi Ololade Olaewe AU - Peter Awonnatemi Agbedemnab AU - Mohammed Muniru Iddrisu Y1 - 2024/04/29 PY - 2024 N1 - https://doi.org/10.11648/j.mcs.20240902.11 DO - 10.11648/j.mcs.20240902.11 T2 - Mathematics and Computer Science JF - Mathematics and Computer Science JO - Mathematics and Computer Science SP - 26 EP - 35 PB - Science Publishing Group SN - 2575-6028 UR - https://doi.org/10.11648/j.mcs.20240902.11 AB - The Hoffman’s algorithm to test equivalency of linear codes is one of the techniques that have been used over the years; it is achieved by a comparison of codewords of the linear codes. However, this comparison technique becomes ineffective in instances where it is applied to linear codes with larger dimensions as it requires much run time complexity, space and size in comparing the codewords of each linear code. This paper proposes an optimised algorithm for testing the equivalency of linear codes, specifically addressing the limitations of the Hoffman method. To assess and compare the efficiencies of the Hoffman algorithm and the optimised algorithm, a set of nine carefully selected linear codes were subjected to equivalency testing. The CPU runtime of both algorithms was recorded using the C++ chrono library. The recorded runtime data was then utilized to create a scatter plot, offering a visual representation of the contrasting trends in CPU runtime between the two algorithms. The plot clearly indicate exponential growth in CPU runtime for the Hoffman algorithm as the length and dimension of the linear codes increases, in contrast, the proposed algorithm showcased a minimal growth in CPU runtime, indicating its superior efficiency and optimised performance. VL - 9 IS - 2 ER -
Department of Information Systems and Technology, C. K. Tedam of University of Technology and Applied Science, Navrongo, Ghana
Department of Information Systems and Technology, C. K. Tedam of University of Technology and Applied Science, Navrongo, Ghana
Department of Mathematics, University for Development Studies, Tamale, Ghana
Information